
- TI nspire
[TI-nspire] 통계, (모평균의) 신뢰 구간 구하는 방법(예제). Statistics - Confidence Intervals
-

- 2024.10.28 - 02:34 2015.12.24 - 11:26 2093 4
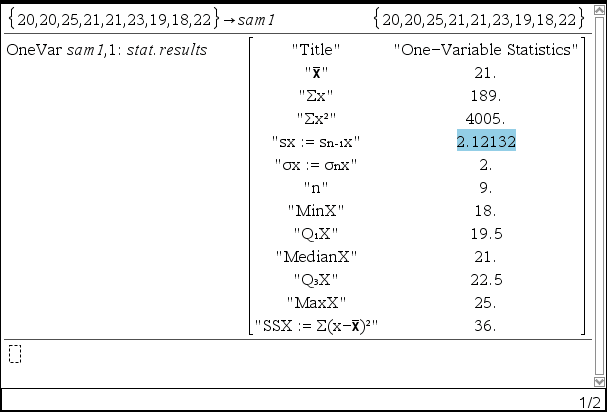
1. 다음 샘플의 모평균에 대한 95% 신뢰구간을 추정하시오.
샘플 = {20,20,25,21,21,23,19,18,22}
문제 출처 : http://math7.tistory.com/66
2. 기본 통계값을 구함 (생략하고 3으로 뛰어도 됨)
【menu】【6】【1】【1】 : One Variable Statistics
3. 신뢰구간 Confidence Intervals 을 구함

- tInterval 프로그램은 DATA 를 직접 이용할 수도 있고, 통계값을 이용할 수도 있다.
tInterval List [, Freq [, CLevel ]]
(Data list input)
tInterval , sx, n[, CLevel]
(Summary stats input)
- 신뢰구간에 대한 요약된 결과는 stat.results 에 저장된다.
다른 통계 프로그램이 사용하는 변수명과 동일하므로 overwrite 될 수 있다.
- sx는 모편차(σx)가 아닌, 표본의 편차임에 주의하자.
- 변수명
Output variableDescriptionstat.CLower, stat.CUpperConfidence interval for an unknown population meanstat.$\overline{x}$Sample mean of the data sequence from the normal random distributionstat.MEMargin of errorstat.dfDegrees of freedomstat.σxSample standard deviationstat.nLength of the data sequence with sample mean
-
25
댓글4
-
-
세상의모든계산기
Sample DATA가 아니라, 통계치가 주어졌을 때
문제:
어느 회사에서 전자기기용 부품인 힌지를 만들고 있습니다.
생산 라인은 안정화되어, 샘플 테스트시 고장이 발생할 때까지 접힐 수 있는 횟수는 정규 분포를 이룹니다.
평균 접히는 횟수는 25만번이고, 표준편차는 2만번으로 나타났습니다.
이번 Lot 생산품중 100개의 샘플을 수거하여 조사하였을 때
제품이 고장날 때까지 접힐 수 있는 평균 횟수의 95% 신뢰구간을 구하세요.
주어진 값
- 모집단 평균 (\(\mu\)): 250,000
- 모집단 표준편차 (\(\sigma\)): 20,000
- 샘플 크기 (\(n\)): 100
- 신뢰수준 = 95% (\( Z = 1.96 \))풀이
1. 표준 오차 (Standard Error, SE) 계산:
$ SE = \dfrac{\sigma}{\sqrt{n}} = \dfrac{20,000}{\sqrt{100}} = \dfrac{20,000}{10} \approx 2,000 $2. 95% 신뢰구간 계산: \[
\text{신뢰 구간} = \bar{X} \pm z_{\alpha/2} \times SE
\]
여기서 \(\bar{X} = \mu = 250,000\)이므로,
\[
\text{신뢰 구간} = 250000 \pm 1.96 \times 2000
\]3. 결과:
$ \text{95% 신뢰구간} = (246080, 253920) $ -
1
세상의모든계산기
6: Statistics - 6: Confidence Intervals - 1: z Interval

Data Input method : Stats

(Data list input) zInterval σ,List[,Freq[,CLevel]]
(Summary stats input) zInterval σ,$ \overline{x} $,n [,CLevel]

-
세상의모든계산기
z-interval vs t-interval 차이점
통계 프로그램에서 t-interval과 z-interval은 모집단의 평균을 추정할 때 사용하는 신뢰 구간 계산 방법으로, 모집단의 분산(또는 표준편차) 정보 유무와 표본 크기에 따라 선택됩니다.
1. z-interval (Z 신뢰 구간)
- 사용 조건: 모집단의 표준편차(\(\sigma\))를 알고 있을 때 사용합니다.
- 표본 크기 요건: 일반적으로 표본 크기가 충분히 큰 경우(보통 \( n \geq 30 \))에 사용하면 정규분포에 가깝게 추정할 수 있습니다.
- 계산: 신뢰 구간의 한계는 표준 정규분포를 이용해 계산됩니다.
- 예: \( \text{z-interval} = \bar{X} \pm Z_{\alpha/2} \times \frac{\sigma}{\sqrt{n}} \)2. t-interval (T 신뢰 구간)
- 사용 조건: 모집단의 표준편차를 모르는 경우 사용하며, 표본 표준편차(\(s\))를 대신 사용합니다.
- 표본 크기 요건: 표본 크기가 작을 때(보통 \( n < 30 \)) 또는 모집단의 분산을 알 수 없을 때 주로 사용됩니다.
- 계산: 신뢰 구간의 한계는 t-분포를 이용해 계산합니다. 이때 자유도(\(n-1\))가 필요합니다.
- 예: \( \text{t-interval} = \bar{X} \pm t_{\alpha/2, \, n-1} \times \frac{s}{\sqrt{n}} \)
세상의모든계산기 님의 최근 댓글
오류 발생 https://www.youtube.com/watch?v=dcg0x5SjETY 위 영상의 문제의 함수를 직접 구해 보았습니다. 그래프로는 잘 확인이 되는데... fmin(), fmax() 함수로 직접 구해보니, 결과가 기대한 것과 다르네요. 구간을 넣지 않으니 fmim, fmax 둘 다에서 오류인 결과를 내놓습니다. 구간을 넣더라도, 적절하게 넣지 않으면, 답이 잘 안나오는 걸 확인할 수 있습니다. fmin 은 그나마 x=0을 기준으로 나누지 않더라도 답이 나오는 편이지만, fmax 는 -10~10 을 구간으로 넣을 때, 가운데 x=0 근방에서 그래프가 위로 솟아오르는 구간은 함수값을 확인하지 않는 듯 합니다. ㄴ fmax가 더 열등해서 그런 것은 아니고, 뒤집어진 모양에서는 반대로 fmin이 못찾습니다. 구간 범위가 커질 경우, 함수에 적용하여 계산하다가 숫자 허용 한계를 벗어나서 overflow 가 나서 오류가 발생할 수도 있는 듯 합니다. 뒤에 점을 넣으니 경고 문구가 추가로 나오긴 했는데, ⚠️ Questionable accuracy. When applicable, try using graphical methods to verify the results. 그래도 실망이네요. * 믿음직한 녀석은 아닌 듯 하니, 주의 표시 ⚠️가 나오든 안나오든, 사용에 주의하시기 바랍니다. 가급적이면 그래프로 검증해 보시는게 좋겠습니다. 2025 10.26 예시 8-1 : 분수식 solve시 오류 예시, 분모에 들어간 X³을 X로 치환해 해결? https://allcalc.org/56074 2025 10.25 fx-570 CW 는 아래 링크에서 https://allcalc.org/56026 2025 10.24 불러오기 할 때 변수값을 먼저 확인하고 싶을 때는 VARIABLE 버튼 【⇄[x]】목록에서 확인하고 Recall 하시면 되고, 변수값을 이미 알고 있을 때는 바로 【⬆️SHIFT】【4】로 (A)를 바로 입력할 수 있습니다. 2025 10.24 fx-570 CW 로 계산하면? - 최종 확인된 결과 값 = 73.049507058478629343538 (23-digits) - 오차 = 6.632809104889414877 × 10^-19 꽤 정밀하게 나온건 맞는데, 시뮬레이션상의 22-digits 와 오차 수준이 비슷함. 왜 그런지는 모르겠음. - 계산기중 정밀도가 높은 편인 HP Prime CAS모드와 비교해도 월등한 정밀도 값을 가짐. 2025 10.24