
- TI nspire
[TI-nspire] 지수 회귀 방정식, Exponential Regression
-

- 2024.10.24 - 19:42 2024.10.23 - 22:54 1816 5

1. 실험 DATA
특정 미생물의 농도는 이론적으로 시간에 따라 다음 식과 같이 변한다고 한다.
$$ C = a \cdot \exp(-b \cdot t) = a \cdot e^{-b \cdot t}$$
실험에서 시간 \( t = 1 \)부터 \( t = 2.5 \)까지의 4개의 데이터 포인트에 대해 미생물 농도 \( C \) 값은 다음과 같다:
\[
\begin{array}{|c|c|}
\hline
t & C \\
\hline
1.0 & 6.05 \\
1.5 & 4.73 \\
2.0 & 3.69 \\
2.5 & 2.86 \\
\hline
\end{array}
\]
2. 회귀 방정식 (Regression)
주어진 식 \( C = a \cdot \exp(-b \cdot t) \)는 지수 함수 형태로, 지수적으로 감소하는 함수이기 때문에 이를 지수적 감소(exponential decay) 모델이라고 부르기도 합니다.
원래의 모형(공식)을 알고 있다면 그 모형과 가장 유사한 방식의 회귀 방정식을 선택하면 되고,
원래의 모형을 모르는 경우라면 데이터 값의 추세를 보고 결정해야 합니다.
위의 예에서는 (데이터 값이 적긴 하지만) 시간에 따라 자연적으로 감소하는 데이터의 형태를 보입니다.
예를 들어 방사성 붕괴나 미생물 성장/감소 등이 이러한 데이터 추세를 가집니다.
이러한 형태의 비선형 회귀 방정식을 지수 회귀 방정식(exponential regression)이라고 합니다.
실험 데이터를 바탕으로 지수 회귀 방정식의 \( a \)와 \( b \) 값을 추정하는 방법은 다음과 같은 단계를 따릅니다.
1. 양변에 자연 로그 취하기
주어진 식을 선형화하기 위해 양변에 자연 로그를 취합니다.
\[
\ln(C) = \ln(a) - b \cdot t
\]
즉, \( \ln(C) \)는 \( t \)에 대한 선형 함수가 됩니다:
\[
\ln(C) = -b \cdot t + \ln(a)
\]
이 식은 기울기가 \( -b \)이고, 절편이 \( \ln(a) \)인 직선 방정식입니다.
2. 데이터를 선형화
실험 데이터에서 \( t \)와 \( C \)의 값을 이용하여 \( \ln(C) \) 값을 계산합니다.
\[
\begin{array}{|c|c|c|}
\hline
t & C & \ln(C) \\
\hline
1.0 & 6.05 & \ln(6.05) = 1.800 \\
1.5 & 4.73 & \ln(4.73) = 1.554 \\
2.0 & 3.69 & \ln(3.69) = 1.306 \\
2.5 & 2.86 & \ln(2.86) = 1.051 \\
\hline
\end{array}
\]
3. 선형 회귀 분석
이제 \( \ln(C) \)와 \( t \)의 관계를 나타내는 선형 방정식의 기울기와 절편을 구하기 위해 선형 회귀 분석을 수행합니다. 선형 회귀는 다음과 같은 방정식을 사용합니다:
- 기울기 \( m \) (즉, \( -b \))는 다음과 같이 계산됩니다:
\[
m = \frac{n \sum t_i \ln(C_i) - \sum t_i \sum \ln(C_i)}{n \sum t_i^2 - (\sum t_i)^2}
\]
여기서:
- \( n = 4 \) (데이터 포인트의 개수)
- \( t_i \)와 \( \ln(C_i) \)는 주어진 데이터에서 가져옵니다.
데이터를 정리
\[
\begin{array}{|c|c|c|}
\hline
t_i & C_i & \ln(C_i) & t_i^2 & t_i \ln(C_i) \\
\hline
1.0 & 6.05 & 1.800 & 1.0 & 1.0 \cdot 1.800 = 1.800 \\
1.5 & 4.73 & 1.554 & 2.25 & 1.5 \cdot 1.554 = 2.331 \\
2.0 & 3.69 & 1.306 & 4.0 & 2.0 \cdot 1.306 = 2.612 \\
2.5 & 2.86 & 1.051 & 6.25 & 2.5 \cdot 1.051 = 2.628 \\
\hline
\end{array}
\]
각 합을 계산
이제 필요한 합들을 계산해보겠습니다:
1. \( \sum t_i = 1.0 + 1.5 + 2.0 + 2.5 = 7.0 \)
2. \( \sum \ln(C_i) = 1.800 + 1.554 + 1.306 + 1.051 = 5.711 \)
3. \( \sum t_i^2 = 1.0 + 2.25 + 4.0 + 6.25 = 13.5 \)
4. \( \sum t_i \ln(C_i) = 1.800 + 2.331 + 2.612 + 2.628 = 9.371 \)
기울기 \( m \) 계산
이제 이 값들을 공식에 대입해 \( m \)을 계산합니다.
\[
m = \dfrac{4 \cdot 9.371 - 7.0 \cdot 5.711}{4 \cdot 13.5 - 7.0^2} = -0.499
\]
- 절편 \( c \) 는 다음과 같이 계산됩니다:
\[
c = \frac{\sum \ln(C_i) - m \sum t_i}{n}
\]
여기에 이미 계산된 값을 대입해보겠습니다:
- \( \sum \ln(C_i) = 5.711 \)
- \( m = -0.499 \)
- \( \sum t_i = 7.0 \)
- \( n = 4 \)
$$ \text{절편 } c = \dfrac{5.711 - (-0.499 \times 7.0)}{4} = 2.301 $$
선형 회귀 방정식
$$ y = mx+c = -0.499 \cdot t + 2.301 $$
4. 지수 회귀 방정식으로 전환 : \( a \)와 \( b \) 구하기
선형 회귀 방정식에서 구한
기울기 \( m = -0.499\)이 \( -b \)이므로, 이를 이용해 \( b = 0.499\) 값을 구할 수 있고,
절편 \( c = ln(a \cdot e^{t})|_{t=0} = \ln(a) \)이므로, 이를 이용해 \( a \) 값을 구할 수 있습니다:
\( a \)는 이 값의 자연 로그 역함수이므로, \( a = \exp(2.301) \approx 9.98 \)입니다.
위 과정을 통해 최종적으로 지수 회귀 방정식을 구하였습니다.
$$ C = 9.98 \cdot \exp(-0.499 \cdot t) = 9.98 \cdot e^{-0.499 \cdot t} $$
3. TI-nspire 의 활용
기본 데이터 값의 입력 및 계산
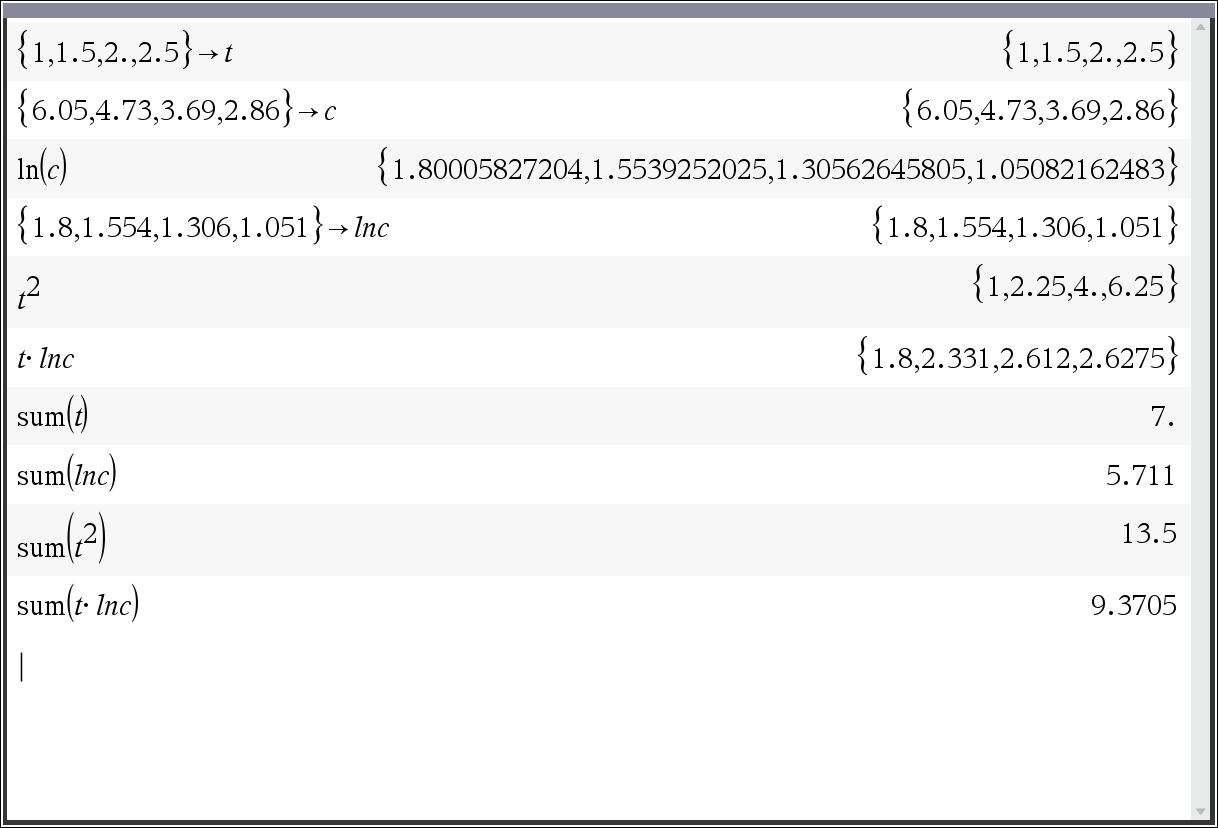
ln(c) 의 선형 회귀 계산

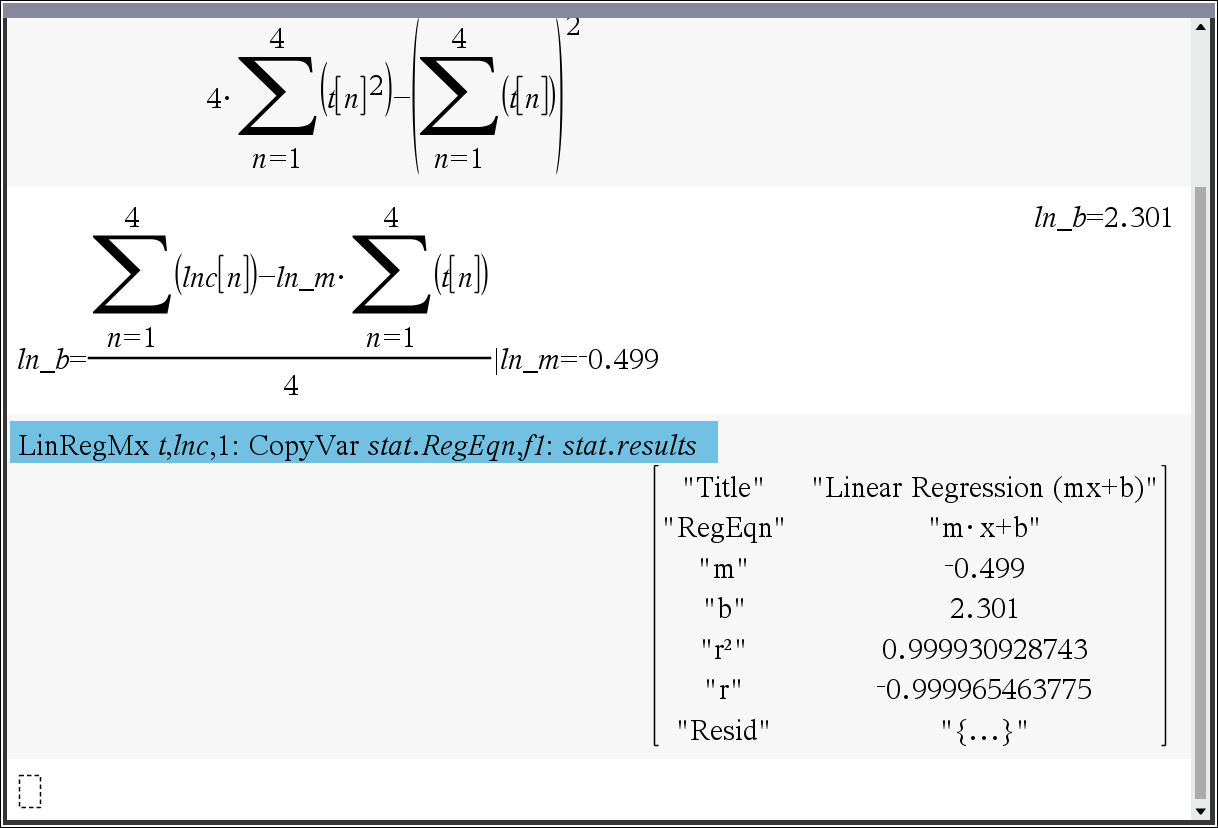
ㄴ ∑ 함수를 말고 sum() 함수에 list 변수를 넣어서 계산하면 간단합니다.
ㄴ 여기서는 단지 공식을 표현하기 위해 사용한 것 뿐입니다.
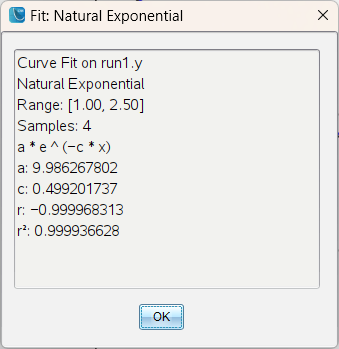
지수 회귀 직접 계산
: 공학용 계산기에는 지수 회귀 방정식 기능이 있기 때문에 앞서 ln(c)를 선형회귀하는 과정이 불필요합니다.

그런데
구해진 TI-nspire 의 지수 회귀 방정식은 $ y = a \cdot e^{-b \cdot t} $ 꼴이 아니고,
$ y = a \cdot b^{t} $ 꼴이기 때문에 마지막으로 한번 더 계산이 필요합니다.
ㄴ solve 또는 ln() 으로 간단하게 찾을 수 있습니다.
한번에 찾을 방법은
(현재 기본 기능만으로는) DataQuest 앱을 이용하는 방법 뿐입니다. : 댓글 참고
불편하면 프로그램(라이브러리)를 만들어야겠죠.
-
25
댓글5
-
세상의모든계산기
최소자승법(최소 제곱법, Least Squares Method)을 행렬로 푸는 방법은 다음과 같은 수식을 사용합니다:
\[
\hat{\beta} = (A^T A)^{-1} A^T y
\]여기서:
- \( A \)는 독립 변수 \( t \)의 행렬
- \( y \)는 종속 변수 \( \ln(C) \)의 벡터
- \( \hat{\beta} \)는 구하려는 계수 벡터로, 기울기 \( b \)와 절편 \( \ln(a) \)가 들어갑니다.1. 행렬 \( A \), \( y \) 정의
주어진 데이터에서 \( t \)와 \( \ln(C) \) 값을 이용하여 다음과 같이 행렬 \( A \)와 벡터 \( y \)를 정의할 수 있습니다:# 데이터:
\[
\begin{array}{|c|c|}
\hline
t & \ln(C) \\
\hline
1.0 & 1.800 \\
1.5 & 1.554 \\
2.0 & 1.306 \\
2.5 & 1.051 \\
\hline
\end{array}
\]행렬 \( A \)는 상수항(절편)을 포함하기 위해 \( 1 \)을 추가하여 다음과 같이 구성됩니다:
\[
A = \begin{pmatrix}
1 & 1.0 \\
1 & 1.5 \\
1 & 2.0 \\
1 & 2.5
\end{pmatrix}
\]벡터 \( y \)는 종속 변수인 \( \ln(C) \) 값을 사용하여 구성됩니다:
\[
y = \begin{pmatrix}
1.800 \\
1.554 \\
1.306 \\
1.051
\end{pmatrix}
\]2. \( A^T A \) 계산
행렬 \( A^T \)는 \( A \)의 전치 행렬이므로 다음과 같습니다:\[
A^T = \begin{pmatrix}
1 & 1 & 1 & 1 \\
1.0 & 1.5 & 2.0 & 2.5
\end{pmatrix}
\]이제 \( A^T A \)를 계산합니다:
\[
A^T A = \begin{pmatrix}
1 & 1 & 1 & 1 \\
1.0 & 1.5 & 2.0 & 2.5
\end{pmatrix}
\begin{pmatrix}
1 & 1.0 \\
1 & 1.5 \\
1 & 2.0 \\
1 & 2.5
\end{pmatrix}
\]\[
A^T A = \begin{pmatrix}
4 & 7.0 \\
7.0 & 13.5
\end{pmatrix}
\]3. \( A^T y \) 계산
다음으로 \( A^T y \)를 계산합니다:\[
A^T y = \begin{pmatrix}
1 & 1 & 1 & 1 \\
1.0 & 1.5 & 2.0 & 2.5
\end{pmatrix}
\begin{pmatrix}
1.800 \\
1.554 \\
1.306 \\
1.051
\end{pmatrix}
\]\[
A^T y = \begin{pmatrix}
1.800 + 1.554 + 1.306 + 1.051 \\
1.0 \cdot 1.800 + 1.5 \cdot 1.554 + 2.0 \cdot 1.306 + 2.5 \cdot 1.051
\end{pmatrix}
\]\[
A^T y = \begin{pmatrix}
5.711 \\
9.371
\end{pmatrix}
\]4. 계수 벡터 \( \hat{\beta} \) 계산
이제 계수 벡터 \( \hat{\beta} \)는 다음과 같이 구할 수 있습니다:\[
\hat{\beta} = (A^T A)^{-1} A^T y
\]먼저 \( A^T A \)의 역행렬을 구합니다:
\[
(A^T A)^{-1} = \frac{1}{(4 \cdot 13.5 - 7.0^2)} \begin{pmatrix} 13.5 & -7.0 \\ -7.0 & 4 \end{pmatrix}
\]\[
(A^T A)^{-1} = \frac{1}{5.0} \begin{pmatrix} 13.5 & -7.0 \\ -7.0 & 4 \end{pmatrix}
\]\[
(A^T A)^{-1} = \begin{pmatrix} 2.7 & -1.4 \\ -1.4 & 0.8 \end{pmatrix}
\]이제 역행렬과 \( A^T y \)를 곱하여 \( \hat{\beta} \)를 구합니다:
\[
\hat{\beta} = \begin{pmatrix} 2.7 & -1.4 \\ -1.4 & 0.8 \end{pmatrix} \begin{pmatrix} 5.711 \\ 9.371 \end{pmatrix}
\]\[
\hat{\beta} = \begin{pmatrix} (2.7 \cdot 5.711) + (-1.4 \cdot 9.371) \\ (-1.4 \cdot 5.711) + (0.8 \cdot 9.371) \end{pmatrix}
\]계산하면:
\[
\hat{\beta} = \begin{pmatrix} 15.4197 - 13.1194 \\ -7.9954 + 7.4968 \end{pmatrix}
\]\[
\hat{\beta} = \begin{pmatrix} 2.3003 \\ -0.4986 \end{pmatrix}
\]5. 결과
따라서, \( \hat{\beta} = \begin{pmatrix} 2.3003 \\ -0.4986 \end{pmatrix} \), 이는 다음을 의미합니다:
- 절편 \( \ln(a) \approx 2.3003 \), 따라서 \( a = \exp(2.3003) \approx 10.0 \)
- 기울기 \( b \approx 0.4986 \)이 방법을 통해 \( a \)와 \( b \) 값을 행렬 계산을 사용하여 구할 수 있습니다.
-
1
-
세상의모든계산기
fx-570 을 이용한 계산 방법
https://allcalc.org/51166
* fx-570 에는 e^X 꼴, A*B^X 꼴 둘 다 있어서 한번에 되는데...
왜 TI-nspire 에는 왜 하나만 있지?
있는데 방법을 모르는 것 뿐인가?
-
1
세상의모든계산기
vernier DataQuest 앱에는 해당 기능이 있습니다. Natural exponential Regression
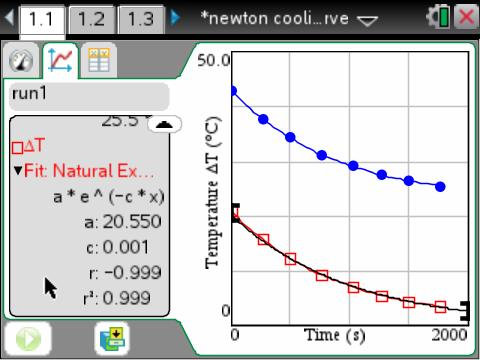
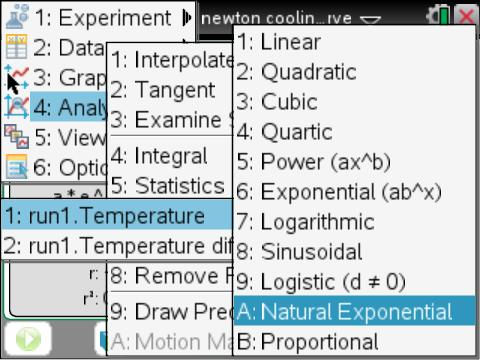
출처 : https://groups.google.com/g/tinspire/c/97sKKp8WVB0
보니까 직접 실험장치를 통해 얻은 데이터만 쓸 수 있는게 아니고,
계산기에 입력된 리스트값도 링크해서 쓸 수 있네요. Link from List
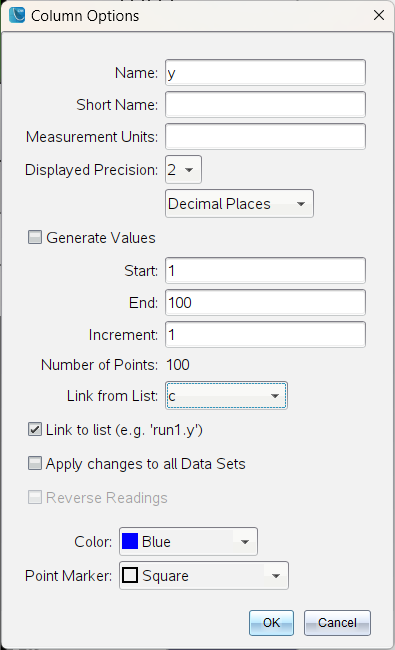
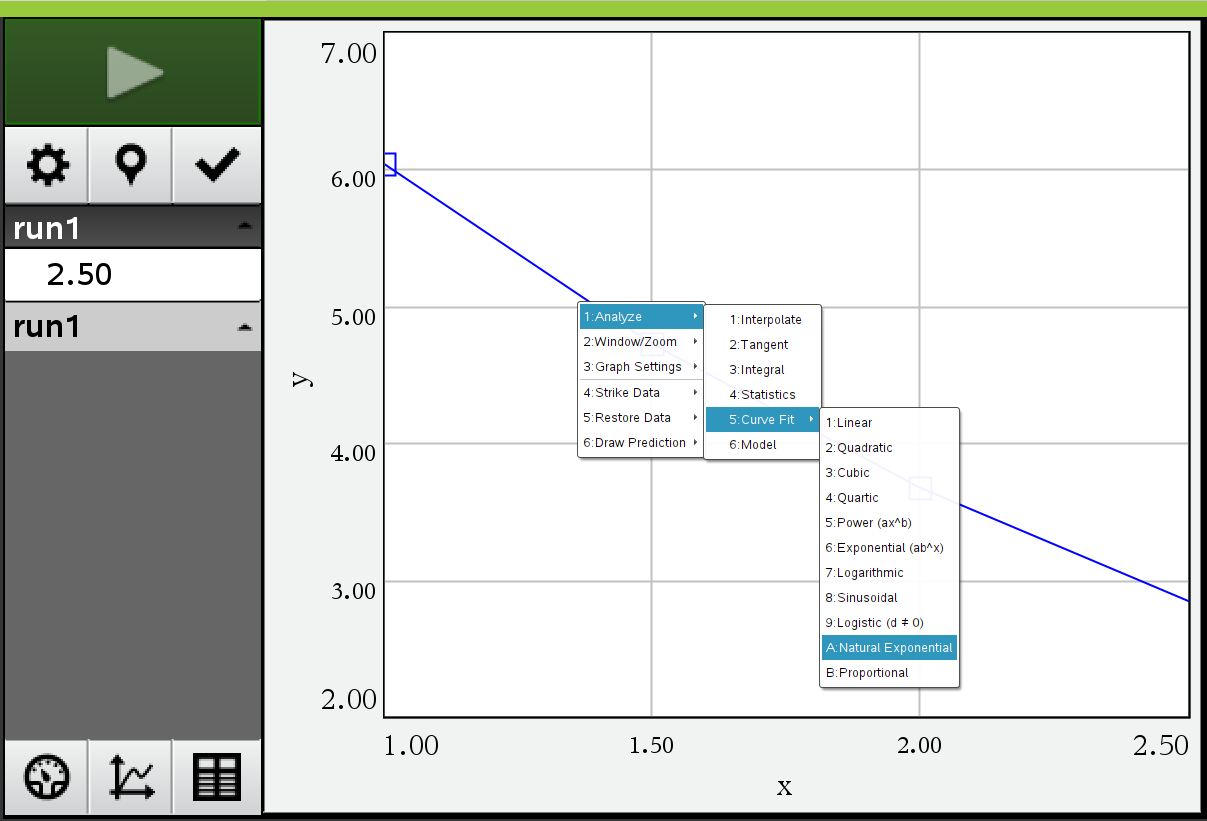
-

세상의모든계산기 님의 최근 댓글
아 그렇네요. 감사합니다. ^^ 2026 04.28 정적분 구간에 미지수가 있고, solve 를 사용할 수 없을 때 그 값을 확인하려면? https://allcalc.org/57087 `SOLVE` 기능 내에 `∫(적분)` 기호를 사용할 수 없을 때 뉴튼-랩슨법을 직접 사용하는 방법 2026 04.15 뉴턴-랩슨 적분 방정식 시각화 v1.0 body { font-family: 'Pretendard', -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto, Helvetica, Arial, sans-serif; display: flex; flex-direction: column; align-items: center; background: #f8f9fa; padding: 40px 20px; margin: 0; color: #333; } .container { background: white; padding: 40px; border-radius: 20px; box-shadow: 0 15px 35px rgba(0,0,0,0.08); max-width: 900px; width: 100%; } header { border-bottom: 2px solid #f1f3f4; margin-bottom: 30px; padding-bottom: 20px; } h1 { color: #1a73e8; margin: 0 0 10px 0; font-size: 1.8em; } p.subtitle { color: #5f6368; margin: 0; font-size: 1.1em; } .equation-box { background: #f1f3f4; padding: 15px; border-radius: 10px; text-align: center; margin-bottom: 30px; font-size: 1.3em; } canvas { border: 1px solid #e0e0e0; border-radius: 12px; background: #fff; width: 100%; height: auto; display: block; } .controls { margin-top: 30px; display: flex; gap: 15px; align-items: center; justify-content: center; flex-wrap: wrap; } button { padding: 12px 25px; border: none; border-radius: 8px; background: #1a73e8; color: white; cursor: pointer; font-weight: 600; font-size: 1em; transition: all 0.2s; box-shadow: 0 2px 5px rgba(26,115,232,0.3); } button:hover { background: #1557b0; transform: translateY(-1px); box-shadow: 0 4px 8px rgba(26,115,232,0.4); } button:active { transform: translateY(0); } button.secondary { background: #5f6368; box-shadow: 0 2px 5px rgba(0,0,0,0.2); } button.secondary:hover { background: #4a4e52; } .status-badge { background: #e8f0fe; color: #1967d2; padding: 8px 15px; border-radius: 20px; font-weight: bold; font-size: 0.9em; } .explanation { margin-top: 40px; padding: 25px; background: #fff8e1; border-left: 5px solid #ffc107; border-radius: 8px; line-height: 1.8; } .explanation h3 { margin-top: 0; color: #856404; } .math-symbol { font-family: 'Times New Roman', serif; font-style: italic; font-weight: bold; color: #d93025; } .code-snippet { background: #202124; color: #e8eaed; padding: 2px 6px; border-radius: 4px; font-family: monospace; } 📊 Newton-Raphson 적분 방정식 시뮬레이터 미분적분학의 기본 정리(FTC)를 이용한 수치해석 시각화 목표 방정식: ∫₀ᴬ (2√x) dx = 20 을 만족하는 A를 찾아라! 계산 시작 (A 추적) 초기화 현재 반복: 0회 💡 시각적 동작 원리 (Newton-Raphson & FTC) Step 1 (오차 측정): 현재 A까지 쌓인 파란색 면적이 목표치(20)와 얼마나 차이나는지 계산합니다. Step 2 (FTC의 마법): 면적의 변화율(미분)은 그 지점의 그래프 높이 f(A)와 같습니다. Step 3 (보정): 다음 A = 현재 A - (면적 오차 / 현재 높이) 공식을 사용하여 A를 이동시킵니다. 결론: 오차를 현재 높이로 나누면, 오차를 메우기 위해 필요한 가로 길이(ΔA)가 나옵니다. 이 과정을 반복하면 정답에 도달합니다! const canvas = document.getElementById('graphCanvas'); const ctx = canvas.getContext('2d'); const iterText = document.getElementById('iterText'); // 수학 설정 const targetArea = 20; const f = (x) => Math.sqrt(x) * 2; // 피적분 함수 f(x) = 2√x const F = (x) => (4/3) * Math.pow(x, 1.5); // 정적분 결과 F(x) = ∫ 2√x dx = 4/3 * x^(3/2) let A = 1.5; // 초기값 let iteration = 0; let animating = false; // 그래프 드로잉 설정 const scale = 50; const offsetX = 60; const offsetY = 380; function drawGrid() { ctx.strokeStyle = '#f1f3f4'; ctx.lineWidth = 1; ctx.beginPath(); for(let i=0; i 2026 04.11 참값 : A = ±2√5 근사값 : A≈±4.472135954999579392818347 2026 04.10 fx-570 ES 입력 결과 초기값 입력 반복 수식 입력 반복 결과 2026 04.10