
- TI nspire
[TI-nspire] 통계, (모평균의) 신뢰 구간 구하는 방법(예제). Statistics - Confidence Intervals
-

- 2024.10.28 - 02:34 2015.12.24 - 11:26 3447 4
1. 다음 샘플의 모평균에 대한 95% 신뢰구간을 추정하시오.
샘플 = {20,20,25,21,21,23,19,18,22}
문제 출처 : http://math7.tistory.com/66
2. 기본 통계값을 구함 (생략하고 3으로 뛰어도 됨)
【menu】【6】【1】【1】 : One Variable Statistics
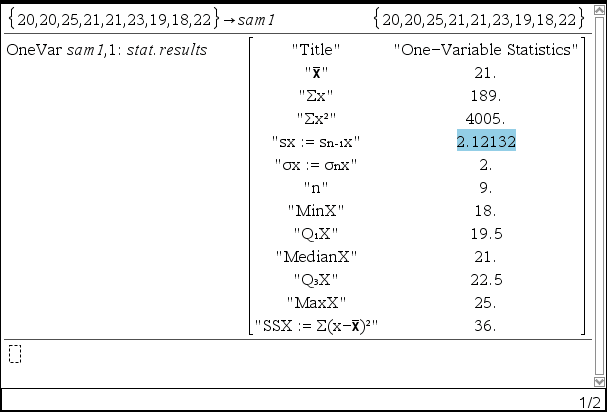
3. 신뢰구간 Confidence Intervals 을 구함

- tInterval 프로그램은 DATA 를 직접 이용할 수도 있고, 통계값을 이용할 수도 있다.
tInterval List [, Freq [, CLevel ]]
(Data list input)
tInterval , sx, n[, CLevel]
(Summary stats input)
- 신뢰구간에 대한 요약된 결과는 stat.results 에 저장된다.
다른 통계 프로그램이 사용하는 변수명과 동일하므로 overwrite 될 수 있다.
- sx는 모편차(σx)가 아닌, 표본의 편차임에 주의하자.
- 변수명
Output variableDescriptionstat.CLower, stat.CUpperConfidence interval for an unknown population meanstat.$\overline{x}$Sample mean of the data sequence from the normal random distributionstat.MEMargin of errorstat.dfDegrees of freedomstat.σxSample standard deviationstat.nLength of the data sequence with sample mean
-
25
댓글4
-
-
세상의모든계산기
Sample DATA가 아니라, 통계치가 주어졌을 때
문제:
어느 회사에서 전자기기용 부품인 힌지를 만들고 있습니다.
생산 라인은 안정화되어, 샘플 테스트시 고장이 발생할 때까지 접힐 수 있는 횟수는 정규 분포를 이룹니다.
평균 접히는 횟수는 25만번이고, 표준편차는 2만번으로 나타났습니다.
이번 Lot 생산품중 100개의 샘플을 수거하여 조사하였을 때
제품이 고장날 때까지 접힐 수 있는 평균 횟수의 95% 신뢰구간을 구하세요.
주어진 값
- 모집단 평균 (\(\mu\)): 250,000
- 모집단 표준편차 (\(\sigma\)): 20,000
- 샘플 크기 (\(n\)): 100
- 신뢰수준 = 95% (\( Z = 1.96 \))풀이
1. 표준 오차 (Standard Error, SE) 계산:
$ SE = \dfrac{\sigma}{\sqrt{n}} = \dfrac{20,000}{\sqrt{100}} = \dfrac{20,000}{10} \approx 2,000 $2. 95% 신뢰구간 계산: \[
\text{신뢰 구간} = \bar{X} \pm z_{\alpha/2} \times SE
\]
여기서 \(\bar{X} = \mu = 250,000\)이므로,
\[
\text{신뢰 구간} = 250000 \pm 1.96 \times 2000
\]3. 결과:
$ \text{95% 신뢰구간} = (246080, 253920) $ -
1
세상의모든계산기
6: Statistics - 6: Confidence Intervals - 1: z Interval

Data Input method : Stats

(Data list input) zInterval σ,List[,Freq[,CLevel]]
(Summary stats input) zInterval σ,$ \overline{x} $,n [,CLevel]

-
세상의모든계산기
z-interval vs t-interval 차이점
통계 프로그램에서 t-interval과 z-interval은 모집단의 평균을 추정할 때 사용하는 신뢰 구간 계산 방법으로, 모집단의 분산(또는 표준편차) 정보 유무와 표본 크기에 따라 선택됩니다.
1. z-interval (Z 신뢰 구간)
- 사용 조건: 모집단의 표준편차(\(\sigma\))를 알고 있을 때 사용합니다.
- 표본 크기 요건: 일반적으로 표본 크기가 충분히 큰 경우(보통 \( n \geq 30 \))에 사용하면 정규분포에 가깝게 추정할 수 있습니다.
- 계산: 신뢰 구간의 한계는 표준 정규분포를 이용해 계산됩니다.
- 예: \( \text{z-interval} = \bar{X} \pm Z_{\alpha/2} \times \frac{\sigma}{\sqrt{n}} \)2. t-interval (T 신뢰 구간)
- 사용 조건: 모집단의 표준편차를 모르는 경우 사용하며, 표본 표준편차(\(s\))를 대신 사용합니다.
- 표본 크기 요건: 표본 크기가 작을 때(보통 \( n < 30 \)) 또는 모집단의 분산을 알 수 없을 때 주로 사용됩니다.
- 계산: 신뢰 구간의 한계는 t-분포를 이용해 계산합니다. 이때 자유도(\(n-1\))가 필요합니다.
- 예: \( \text{t-interval} = \bar{X} \pm t_{\alpha/2, \, n-1} \times \frac{s}{\sqrt{n}} \)
세상의모든계산기 님의 최근 댓글
아 그렇네요. 감사합니다. ^^ 2026 04.28 정적분 구간에 미지수가 있고, solve 를 사용할 수 없을 때 그 값을 확인하려면? https://allcalc.org/57087 `SOLVE` 기능 내에 `∫(적분)` 기호를 사용할 수 없을 때 뉴튼-랩슨법을 직접 사용하는 방법 2026 04.15 뉴턴-랩슨 적분 방정식 시각화 v1.0 body { font-family: 'Pretendard', -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto, Helvetica, Arial, sans-serif; display: flex; flex-direction: column; align-items: center; background: #f8f9fa; padding: 40px 20px; margin: 0; color: #333; } .container { background: white; padding: 40px; border-radius: 20px; box-shadow: 0 15px 35px rgba(0,0,0,0.08); max-width: 900px; width: 100%; } header { border-bottom: 2px solid #f1f3f4; margin-bottom: 30px; padding-bottom: 20px; } h1 { color: #1a73e8; margin: 0 0 10px 0; font-size: 1.8em; } p.subtitle { color: #5f6368; margin: 0; font-size: 1.1em; } .equation-box { background: #f1f3f4; padding: 15px; border-radius: 10px; text-align: center; margin-bottom: 30px; font-size: 1.3em; } canvas { border: 1px solid #e0e0e0; border-radius: 12px; background: #fff; width: 100%; height: auto; display: block; } .controls { margin-top: 30px; display: flex; gap: 15px; align-items: center; justify-content: center; flex-wrap: wrap; } button { padding: 12px 25px; border: none; border-radius: 8px; background: #1a73e8; color: white; cursor: pointer; font-weight: 600; font-size: 1em; transition: all 0.2s; box-shadow: 0 2px 5px rgba(26,115,232,0.3); } button:hover { background: #1557b0; transform: translateY(-1px); box-shadow: 0 4px 8px rgba(26,115,232,0.4); } button:active { transform: translateY(0); } button.secondary { background: #5f6368; box-shadow: 0 2px 5px rgba(0,0,0,0.2); } button.secondary:hover { background: #4a4e52; } .status-badge { background: #e8f0fe; color: #1967d2; padding: 8px 15px; border-radius: 20px; font-weight: bold; font-size: 0.9em; } .explanation { margin-top: 40px; padding: 25px; background: #fff8e1; border-left: 5px solid #ffc107; border-radius: 8px; line-height: 1.8; } .explanation h3 { margin-top: 0; color: #856404; } .math-symbol { font-family: 'Times New Roman', serif; font-style: italic; font-weight: bold; color: #d93025; } .code-snippet { background: #202124; color: #e8eaed; padding: 2px 6px; border-radius: 4px; font-family: monospace; } 📊 Newton-Raphson 적분 방정식 시뮬레이터 미분적분학의 기본 정리(FTC)를 이용한 수치해석 시각화 목표 방정식: ∫₀ᴬ (2√x) dx = 20 을 만족하는 A를 찾아라! 계산 시작 (A 추적) 초기화 현재 반복: 0회 💡 시각적 동작 원리 (Newton-Raphson & FTC) Step 1 (오차 측정): 현재 A까지 쌓인 파란색 면적이 목표치(20)와 얼마나 차이나는지 계산합니다. Step 2 (FTC의 마법): 면적의 변화율(미분)은 그 지점의 그래프 높이 f(A)와 같습니다. Step 3 (보정): 다음 A = 현재 A - (면적 오차 / 현재 높이) 공식을 사용하여 A를 이동시킵니다. 결론: 오차를 현재 높이로 나누면, 오차를 메우기 위해 필요한 가로 길이(ΔA)가 나옵니다. 이 과정을 반복하면 정답에 도달합니다! const canvas = document.getElementById('graphCanvas'); const ctx = canvas.getContext('2d'); const iterText = document.getElementById('iterText'); // 수학 설정 const targetArea = 20; const f = (x) => Math.sqrt(x) * 2; // 피적분 함수 f(x) = 2√x const F = (x) => (4/3) * Math.pow(x, 1.5); // 정적분 결과 F(x) = ∫ 2√x dx = 4/3 * x^(3/2) let A = 1.5; // 초기값 let iteration = 0; let animating = false; // 그래프 드로잉 설정 const scale = 50; const offsetX = 60; const offsetY = 380; function drawGrid() { ctx.strokeStyle = '#f1f3f4'; ctx.lineWidth = 1; ctx.beginPath(); for(let i=0; i 2026 04.11 참값 : A = ±2√5 근사값 : A≈±4.472135954999579392818347 2026 04.10 fx-570 ES 입력 결과 초기값 입력 반복 수식 입력 반복 결과 2026 04.10