
- TI nspire
[TI-nspire] 통계에서 사용하는 Category List 기능은?
-

- 2024.10.24 - 17:49 2024.10.24 - 15:14 1867 1
통계 관련한 각종 함수나 프로그램에서는 각종 변수와 리스트를 입력받습니다.
없으면 에러가 나는 필수 인자들도 있지만, 없더라도 계산 결과에 지장이 없는 선택옵션도 있습니다.
Category List / Include Categories 가 바로 선택 옵션에 해당합니다.
그런데 궁금하더군요. 뭐하는 기능인지??
범주, 분류 하는 기능이긴 할텐데... 구체적으로 어떤 개념으로 사용하는지는 감이 오지 않습니다.
Reference Guide 의 설명
OneVar [n,]X1,X2[X3[,…[,X20]]]
Category는 X 값에 대응하는 숫자 카테고리 코드 목록입니다.
Include는 하나 이상의 카테고리 코드가 포함된 목록으로, 이 목록에 포함된 카테고리 코드에 해당하는 데이터 항목만 계산에 포함됩니다.
X, Freq, 또는 Category 목록에 비어 있는(무효한) 항목이 있을 경우, 해당 항목에 대응하는 모든 목록의 요소는 무효 처리됩니다.
X1부터 X20까지의 목록 중 어느 하나에 비어 있는 항목이 있으면, 해당 항목에 대응하는 모든 목록의 요소는 무효 처리됩니다.
우선 Spreadsheet 에 DATA를 입력해 봅니다.
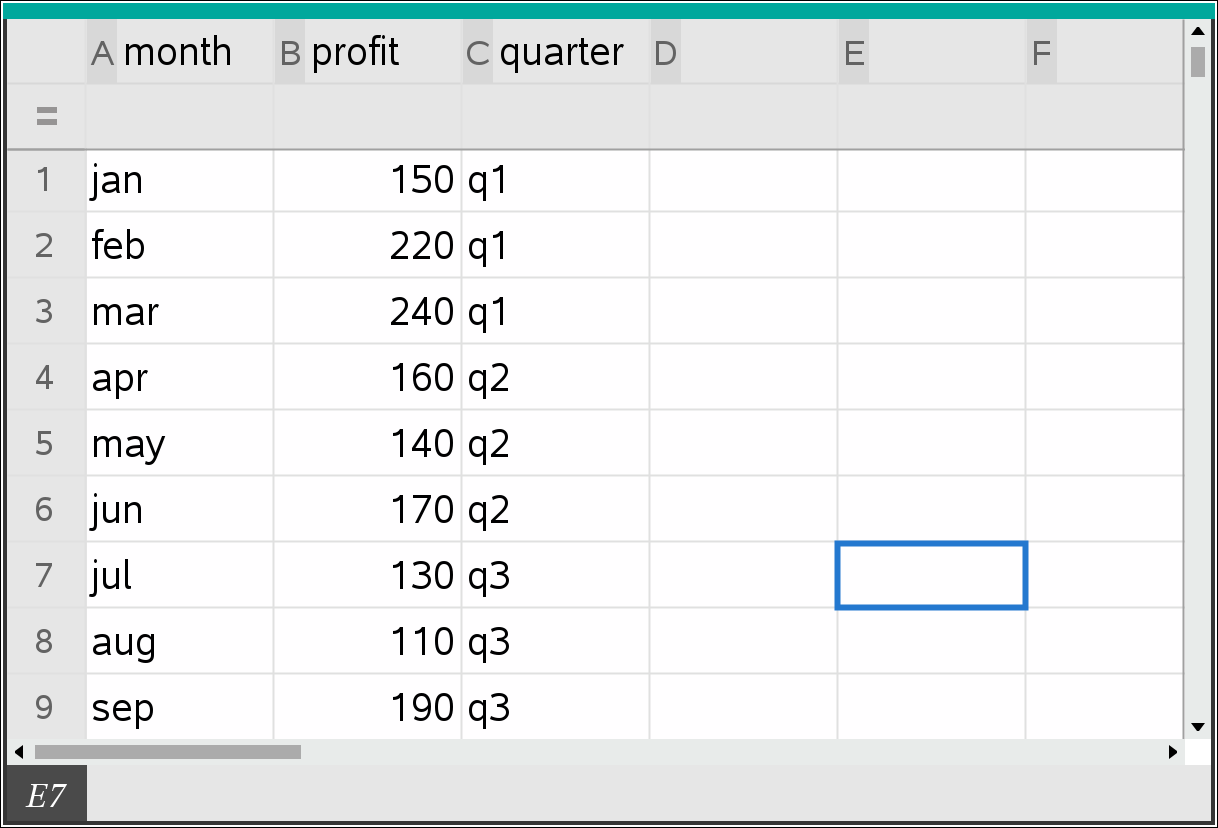
month := {jan,feb,mar,apr,may,jun,jul,aug,sep,oct,nov,dec}
profit := {150,220,240,160,140,170,130,110,190,170,170,140}
quarter := {q1,q1,q1,q2,q2,q2,q3,q3,q3,q4,q4,q4}
1-var 분석을 해 보겠습니다.
- 카네고리에만 값을 넣으면 결과에 변함이 없습니다.


숫자 카테고리 코드 목록이라고 나와 있으니 카네고리 리스트를 숫자로 변경해 봅니다.
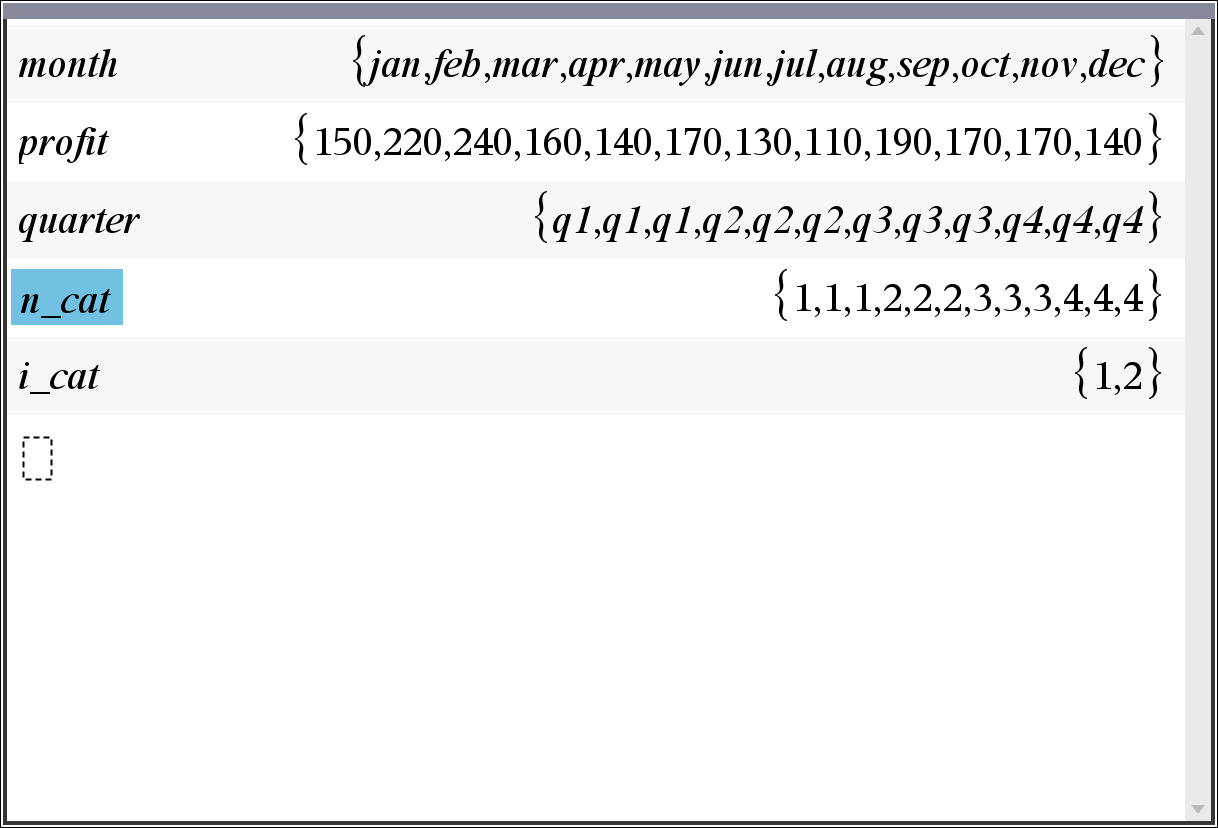


아... 이렇게 쓰는 거로군요.
그런데 guidebook 내용과 다르게 숫자만 되는 것은 아닙니다. 문자변수로도 카테고리 지정이 가능합니다.

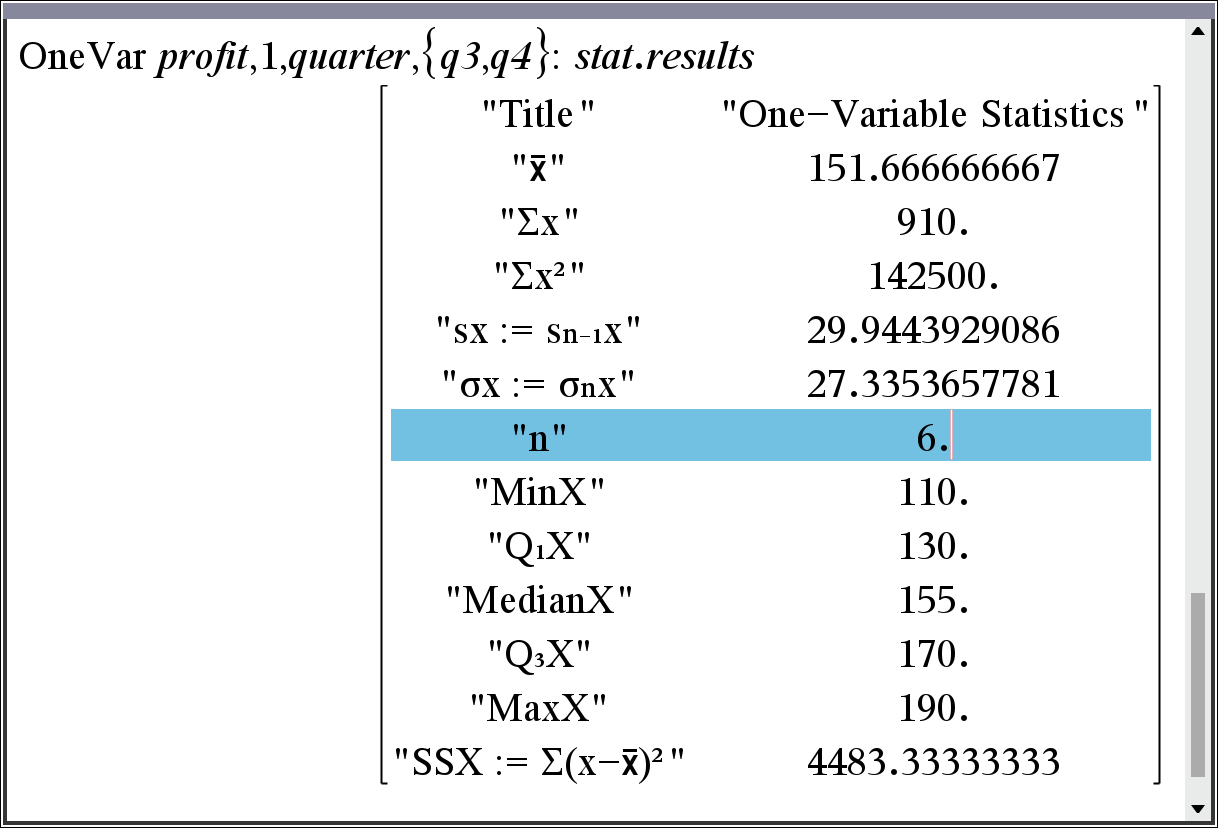
통계 그래프 페이지에서도 확인이 되긴 하는데...
분기별 평균 등으로 확인할 수 있을지?
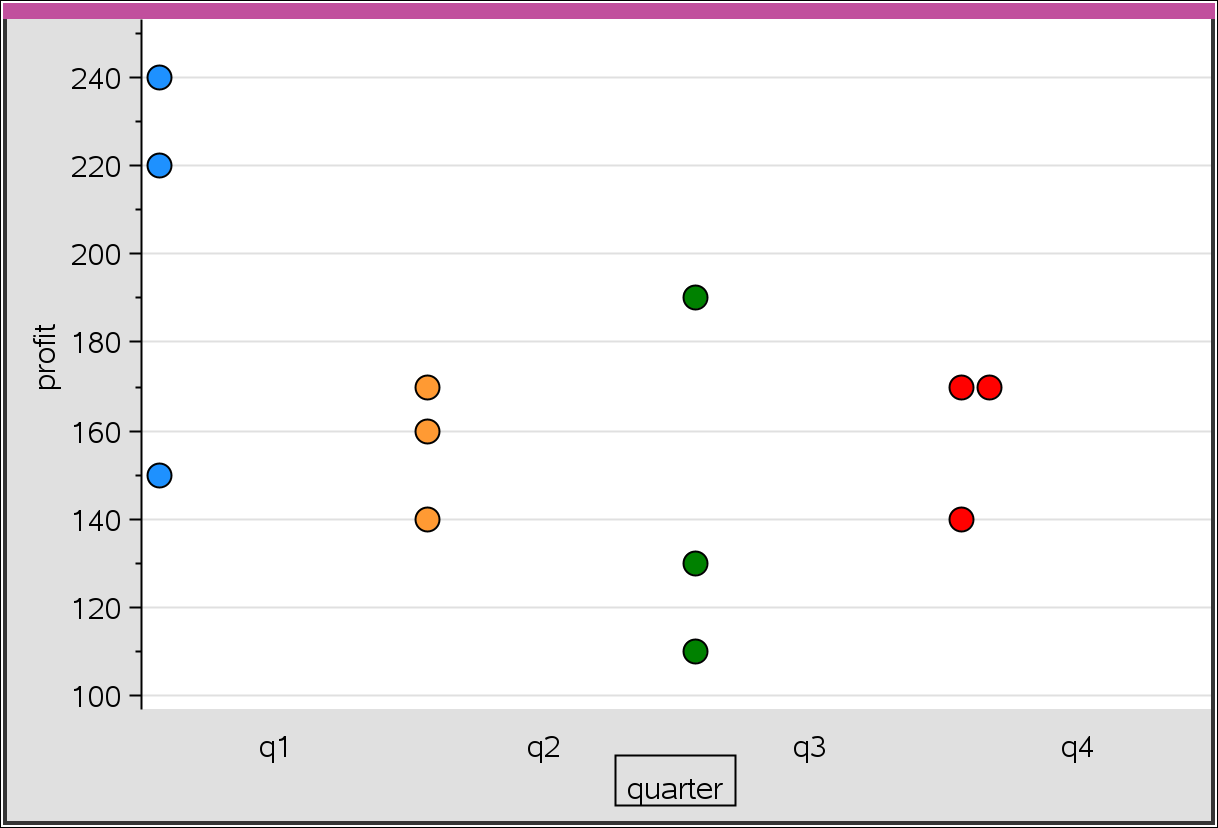
기본 기능으로는 box plot 으로 보는 정도가 최선이고,
평균값 등의 수치를 category별로 일목요연하게 정리해 주는 기능은 없네요.
-
25
세상의모든계산기 님의 최근 댓글
아 그렇네요. 감사합니다. ^^ 2026 04.28 정적분 구간에 미지수가 있고, solve 를 사용할 수 없을 때 그 값을 확인하려면? https://allcalc.org/57087 `SOLVE` 기능 내에 `∫(적분)` 기호를 사용할 수 없을 때 뉴튼-랩슨법을 직접 사용하는 방법 2026 04.15 뉴턴-랩슨 적분 방정식 시각화 v1.0 body { font-family: 'Pretendard', -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto, Helvetica, Arial, sans-serif; display: flex; flex-direction: column; align-items: center; background: #f8f9fa; padding: 40px 20px; margin: 0; color: #333; } .container { background: white; padding: 40px; border-radius: 20px; box-shadow: 0 15px 35px rgba(0,0,0,0.08); max-width: 900px; width: 100%; } header { border-bottom: 2px solid #f1f3f4; margin-bottom: 30px; padding-bottom: 20px; } h1 { color: #1a73e8; margin: 0 0 10px 0; font-size: 1.8em; } p.subtitle { color: #5f6368; margin: 0; font-size: 1.1em; } .equation-box { background: #f1f3f4; padding: 15px; border-radius: 10px; text-align: center; margin-bottom: 30px; font-size: 1.3em; } canvas { border: 1px solid #e0e0e0; border-radius: 12px; background: #fff; width: 100%; height: auto; display: block; } .controls { margin-top: 30px; display: flex; gap: 15px; align-items: center; justify-content: center; flex-wrap: wrap; } button { padding: 12px 25px; border: none; border-radius: 8px; background: #1a73e8; color: white; cursor: pointer; font-weight: 600; font-size: 1em; transition: all 0.2s; box-shadow: 0 2px 5px rgba(26,115,232,0.3); } button:hover { background: #1557b0; transform: translateY(-1px); box-shadow: 0 4px 8px rgba(26,115,232,0.4); } button:active { transform: translateY(0); } button.secondary { background: #5f6368; box-shadow: 0 2px 5px rgba(0,0,0,0.2); } button.secondary:hover { background: #4a4e52; } .status-badge { background: #e8f0fe; color: #1967d2; padding: 8px 15px; border-radius: 20px; font-weight: bold; font-size: 0.9em; } .explanation { margin-top: 40px; padding: 25px; background: #fff8e1; border-left: 5px solid #ffc107; border-radius: 8px; line-height: 1.8; } .explanation h3 { margin-top: 0; color: #856404; } .math-symbol { font-family: 'Times New Roman', serif; font-style: italic; font-weight: bold; color: #d93025; } .code-snippet { background: #202124; color: #e8eaed; padding: 2px 6px; border-radius: 4px; font-family: monospace; } 📊 Newton-Raphson 적분 방정식 시뮬레이터 미분적분학의 기본 정리(FTC)를 이용한 수치해석 시각화 목표 방정식: ∫₀ᴬ (2√x) dx = 20 을 만족하는 A를 찾아라! 계산 시작 (A 추적) 초기화 현재 반복: 0회 💡 시각적 동작 원리 (Newton-Raphson & FTC) Step 1 (오차 측정): 현재 A까지 쌓인 파란색 면적이 목표치(20)와 얼마나 차이나는지 계산합니다. Step 2 (FTC의 마법): 면적의 변화율(미분)은 그 지점의 그래프 높이 f(A)와 같습니다. Step 3 (보정): 다음 A = 현재 A - (면적 오차 / 현재 높이) 공식을 사용하여 A를 이동시킵니다. 결론: 오차를 현재 높이로 나누면, 오차를 메우기 위해 필요한 가로 길이(ΔA)가 나옵니다. 이 과정을 반복하면 정답에 도달합니다! const canvas = document.getElementById('graphCanvas'); const ctx = canvas.getContext('2d'); const iterText = document.getElementById('iterText'); // 수학 설정 const targetArea = 20; const f = (x) => Math.sqrt(x) * 2; // 피적분 함수 f(x) = 2√x const F = (x) => (4/3) * Math.pow(x, 1.5); // 정적분 결과 F(x) = ∫ 2√x dx = 4/3 * x^(3/2) let A = 1.5; // 초기값 let iteration = 0; let animating = false; // 그래프 드로잉 설정 const scale = 50; const offsetX = 60; const offsetY = 380; function drawGrid() { ctx.strokeStyle = '#f1f3f4'; ctx.lineWidth = 1; ctx.beginPath(); for(let i=0; i 2026 04.11 참값 : A = ±2√5 근사값 : A≈±4.472135954999579392818347 2026 04.10 fx-570 ES 입력 결과 초기값 입력 반복 수식 입력 반복 결과 2026 04.10