
- CASIO 570
[fx-570ES] STAT 통계 - 편차제곱의 합. SSX 또는 SSY
-

- 2024.09.19 - 09:50 2024.09.18 - 20:37 756 1
편차제곱의 합은 통계학에서 데이터의 분산과 표준편차를 계산할 때 중요한 개념입니다. 이를 이해하기 위해 먼저 편차를 정의해야 합니다.

1. 편차 (Deviation):
편차는 각 데이터 값이 평균에서 얼마나 떨어져 있는지를 나타내는 값입니다. 수식으로는 다음과 같습니다.
\[
\text{편차} = x_i - \mu
\]
여기서:
- \( x_i \)는 각 데이터 값
- \( \mu \)는 데이터 값들의 평균입니다.
2. 편차제곱 (Squared Deviation):
편차는 양수 또는 음수일 수 있기 때문에, 이 값들을 제곱하여 편차제곱을 구합니다. 이는 음수와 양수를 구분하지 않고 편차의 크기만을 평가할 수 있게 합니다.
\[
\text{편차제곱} = (x_i - \mu)^2
\]
3. 편차제곱의 합 (Sum of Squared Deviations):
편차제곱을 모든 데이터에 대해 구한 후, 이들을 모두 더한 값이 편차제곱의 합입니다. 이는 데이터가 평균으로부터 얼마나 퍼져 있는지를 나타내는 중요한 값입니다.
\[
\text{편차제곱의 합} = \sum_{i=1}^{n} (x_i - \mu)^2
\]
이 값은 분산(Variance) 및 표준편차(Standard Deviation)를 구하는 데 사용됩니다.
- 분산은 편차제곱의 합을 데이터 개수로 나눈 값입니다.
- 표준편차는 분산의 제곱근입니다.
- 약어 표시
- SSX: 독립 변수 XXX에 대한 편차제곱의 합 (Sum of Squares for XXX).
- SST: 총 편차제곱의 합 (Total Sum of Squares).
- SSR: 회귀의 편차제곱의 합 (Sum of Squares for Regression).
- SSE: 잔차의 편차제곱의 합 (Sum of Squares for Error).
4. SSX와 기본 통계 변수들 간의 관계
1. SSX와 평균:
- SSX는 변수 X의 각 데이터 값이 평균 $ \mu \ $ 에서 얼마나 떨어져 있는지를 제곱한 값의 합입니다. 즉, 편차를 제곱하고 모두 더한 것이 SSX입니다.
\[
SSX = \sum_{i=1}^{n} (x_i - \bar{x})^2
\]
여기서 \(x_i\)는 각 데이터 값, \(\bar{x}\)는 데이터의 평균입니다.
2. SSX와 분산:
- 분산(Variance)은 SSX를 데이터 개수 \(n\)로 나눈 값입니다.
\[
\text{분산} (\sigma^2) = \frac{SSX}{n}
\]
분산은 데이터 값들이 평균에서 얼마나 퍼져 있는지를 나타내는 지표로, SSX를 표본 크기 \(n\)으로 나누어 계산합니다.
만약 표본 분산(sample variance)을 구하려면 \(n\) 대신 \(n - 1\)을 사용합니다.
\[
\text{표본 분산} (s^2) = \frac{SSX}{n - 1}
\]
3. SSX와 표준편차:
- 표준편차(Standard Deviation)는 분산의 제곱근입니다. 따라서, SSX를 이용해 분산을 구한 후, 표준편차를 구할 수 있습니다.
\[
\text{표준편차} (\sigma) = \sqrt{\frac{SSX}{n}}
\]
표본 표준편차(sample standard deviation)의 경우도 마찬가지로 표본 분산의 제곱근을 구합니다.
\[
\text{표본 표준편차} (s) = \sqrt{\frac{SSX}{n - 1}}
\]
요약
SSX는 기본 통계 변수들과 다음과 같은 관계를 가집니다:
- SSX는 평균에서 각 데이터 값들의 편차제곱을 모두 더한 값입니다.
- 분산은 SSX를 데이터의 개수로 나눈 값이며, 데이터 값들의 변동성을 나타냅니다.
- 표준편차는 SSX를 기반으로 구한 분산의 제곱근으로, 데이터가 평균에서 얼마나 퍼져 있는지 보여줍니다.
예시
- 데이터: \( [2, 4, 6, 8] \)
- 평균: \( \bar{x} = 5 \)
- SSX:
\[
SSX = (2-5)^2 + (4-5)^2 + (6-5)^2 + (8-5)^2 = 9 + 1 + 1 + 9 = 20
\]
- 분산: \( \sigma^2 = \frac{SSX}{n} = \frac{20}{4} = 5 \)
- 표준편차: \( \sigma = \sqrt{5} \approx 2.236 \)


 : 1-VAR
: 1-VAR





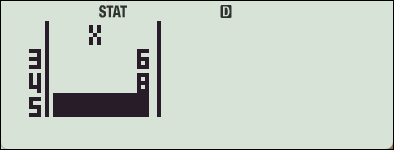

 : Var
: Var
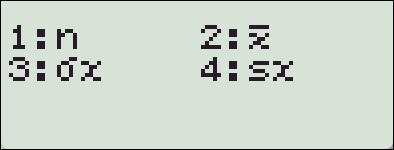
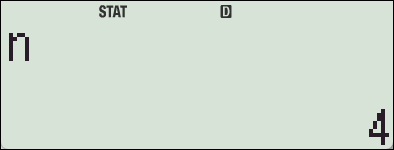
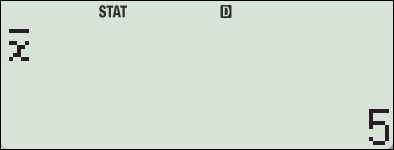
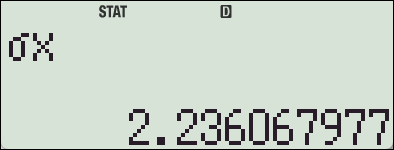

4. fx-570 ES 기종에서의 SSX, SSY
카시오 fx-570ES Plus 계산기에는 편차제곱의 합 (SSX, Sum of Squared Deviations)을 직접 구해주는 함수나 변수가 내장되어 있지 않습니다.
https://allcalc.org/5615 - [fx-570][fx-350] STAT 통계 모드 진행 과정 (변수 분석, 회귀 분석 등 전반)
일반적으로 통계 계산을 위해 제공되는 주요 기능들은 평균, 분산, 표준편차 등을 계산하는 것이기 때문에,
표준편차의 계산을 위한 중간 과정인 '분산'이나 '편차제곱의 합'은 통계 변수로 따로 저장되지 않았습니다.
(어떤 변수를 저장할지의 결정은 계산기 모델마다 다를 수 있습니다)
따라서 위에서 일일이 따로 계산하거나, 위의 공식(2. 분산) 을 반대로 계산하여 이미 계산되어 저장된 통계변수를 활용하여 값을 구할 수 있습니다.
\[
\text{편차제곱의 합}, SSX = \sigma^2 \cdot n = s^2 \cdot \left(n - 1\right)
\]
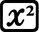

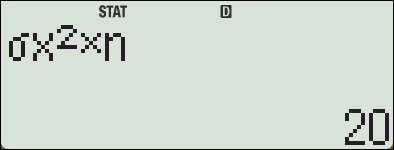
-
25
댓글1
-
세상의모든계산기
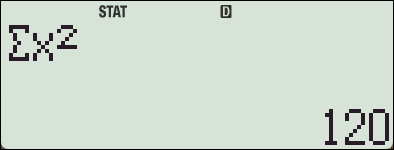
편차제곱의 합 SS 와
Sum 목록에 있는 x^2의 합은 서로 다른 값입니다.
: Sum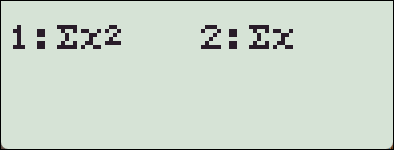
세상의모든계산기 님의 최근 댓글
fx-570 CW 는 아래 링크에서 https://allcalc.org/56026 2025 10.24 불러오기 할 때 변수값을 먼저 확인하고 싶을 때는 VARIABLE 버튼 【⇄[x]】목록에서 확인하고 Recall 하시면 되고, 변수값을 이미 알고 있을 때는 바로 【⬆️SHIFT】【4】로 (A)를 바로 입력할 수 있습니다. 2025 10.24 fx-570 CW 로 계산하면? - 최종 확인된 결과 값 = 73.049507058478629343538 (23-digits) - 오차 = 6.632809104889414877 × 10^-19 꽤 정밀하게 나온건 맞는데, 시뮬레이션상의 22-digits 와 오차 수준이 비슷함. 왜 그런지는 모르겠음. - 계산기중 정밀도가 높은 편인 HP Prime CAS모드와 비교해도 월등한 정밀도 값을 가짐. 2025 10.24 HP Prime 에서 <Home> 73.0495070344 (12-decimal-digits) // python 시뮬레이션과 일치 <CAS> 21자리까지 나와서 이상하다 싶었는데, Ans- 에서 자릿수를 더 늘려서 빼보니, 뒷부분 숫자가 아예 바뀌어버림. 버그인가? (전) 73.0495070584718691243 (21-digits ????) (후) 73.0495070584718500814401 (24-digits ????) 찾아보니 버그는 아니고, CAS에서는 십진수가 아니라 2진수(bit) 단위로 처리한다고 함. Giac uses 48 bits mantissa from the 53 bits from IEEE double. The reason is that Giac stores CAS data (gen type) in 64 bits and 5 bits are used for the data type (24 types are available). We therefore loose 5 bits (the 5 low bits are reset to 0 when a double is retrieved from a gen). 출처 : https://www.hpmuseum.org/cgi-bin/archv021.cgi?read=255657 일단 오차를 놓고 보면 16-decimal-digits 수준으로 보임. 2025 10.23 khiCAS 에서 HP 39gII 에 올린 khiCAS는 254! 까지 계산 가능, 255! 부터는 ∞ fx-9750GIII 에 올린 khiCAS는 factorial(533) => 425760136423128437▷ // 정답, 10진수 1224자리 factorial(534) => Object too large 2025 10.23