
- CASIO 공통
[fx-570][fx-350] STAT 통계 모드 진행 과정 (변수 분석, 회귀 분석 등 전반)
-

- 2025.09.23 - 14:40 2015.03.12 - 09:47 35008 21
1. 통계 변수 분석 (STAT) 모드란?
통계 계산 모드는 통계 데이터를 입력하는 것만으로, 각종 통계 결과를 쉽게 확인할 수 있는 모드입니다.
(350이나 570 등의) 기초형 계산기에서는 아주 기본적인 통계변수의 결과만 찾아줍니다.
* 국내 ES PLUS 계열에는 분포Distribution 기능이 빠져 있으니,
통계 목적으로는 fx-570EX 급을 구입하시는게 좋겠습니다. 결과 확인도 훨씬 수월합니다. fx-570 CW 도 비슷합니다.
(그래핑 계산기급 이상의) 고급형 계산기에서는 Graph / Plot / Datagram 등을 그려주는 기능이 있습니다.
2. 주의사항
- [fx-350]기종과 [fx-570]기종은 STAT 모드 진입 버튼이 다릅니다. 진입 후에는 차이가 없습니다.
예) 1-VAR(1변수분석)
[fx-570ES]는 【MODE】【3】【1】
[fx-570EX]는 【MENU】【6】【1】
[fx-350ES]는 【MODE】【2】【1】
이하, 본문은 [fx-570ES] 기종을 기준으로 설명되어 있으므로 감안하고 읽으시기 바랍니다.
- 모드가 변경되면 이미 입력한 데이터 값이 '초기화'될 수가 있습니다. 따라서 모드 변경시 주의하셔야 합니다.
예를 들어 【MODE】【3】【2】 로 선형회귀 결과를 확인하다가, 동일한 데이터로 다른 타입에 속하는 지수회귀 결과를 보려고 할 때, 【MODE】【3】【6】 을 누르면 선형회귀에서 입력해놓은 데이터가 다 날아갑니다. 따라서 【AC】 누른 후에 【SHIFT】【1】【1】 을 눌러서 STAT 모드 내부에서 Type만을 변경하여야 합니다.
- [MS] 기종은 [ES] 기종과 사용 방법이 약간 다를 수 있습니다. [EX] 기종도 마찬가지구요.
https://allcalc.org/8114
본문은 [ES] 기종을 기준으로 설명되어 있습니다.
3. 계산 진행 과정 (입력 순서)
계산기의 통계 모드는 처음 사용할 때 굉장히 복잡해 보일 수 있는데, 핵심과정만 구분할 수 있으면 하나도 어렵지 않습니다.
- TYPE 결정 【SHIFT】【1】 【1】
여러 통계 모드 중에서 어떤 (Type의) 기능을 사용할지 결정
https://allcalc.org/6167
* Type 은 통계 계산 과정 중 언제라도 변경할 수 있습니다. 이 때 DATA를 초기화할지 결정할 수 있습니다.
- DATA 입력/수정/확인【SHIFT】【1】 【2】
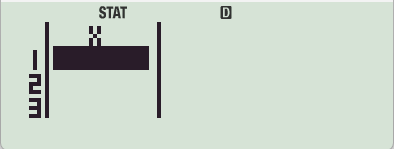
데이터를 입력하고 수정합니다.
입력한 데이터는 통계(STAT)모드 내에서 언제라도 수정 가능합니다.
모드 변경으로만 넘어가지 않으면 입력해 둔 DATA값이 초기화되지 않습니다.
- 결과 확인
【AC】 를 눌러서 통계 DATA 입력모드에서 나옵니다.
【SHIFT】【1】 을 눌러서 (Sum, Var 등의) 통계 변수값을 확인합니다.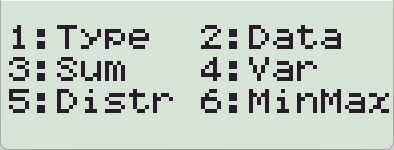
(EX 기종은 【OPTN】 을 눌러서 통계 변수값을 확인합니다.)
4. 통계 분석 결과 (사용가능한 변수)
| Sum |
|
| Var |
|
| Reg |
|
※ 통계 모드에 따라 사용 가능한 변수 종류가 달라집니다.
-
25
댓글21
-
세상의모든계산기
예시 : 1-VAR(1변수 분석) [fx-570ES]
- 문제 : 데이터가 {1, 2, 3, 4, 5, 6} 일 때, 표본 표준편차를 구한다.
- 계산기 입력 :
【MODE】【3】【1】 : 1-VAR, DATA 입력 화면으로 이동
【1】【=】【2】【=】【중간생략】【6】【=】 : DATA 입력 완료
【AC】 : STAT 기본 화면으로 이동
【SHIFT】【1】【4】 Var : 원하는 통계 변수 선택 (문제에서는 표본의 표준편차)
【4】【=】 : sx (표본표준편차) 선택
- 결과의 확인
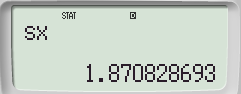
- 모표준편차와 표본표준편차를 구분하여 사용합니다.
- ∑x 나 ∑x² 와 같은 변수는 【SHIFT】【1】【3】 Sum 항목에서 찾아볼 수 있습니다.
- 문제 : 데이터가 {1, 2, 3, 4, 5, 6} 일 때, 표본 표준편차를 구한다.
-
세상의모든계산기
편차 제곱합(SSy) 구하는 방법
문제
회귀(REG) 계산에서 DATA를 입력하고,
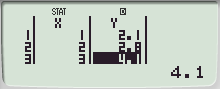
y의 편차 제곱합 = ∑((yi-y바)²) 을 구하려 함.
(1 변수 DATA 라면 REG 모드로 갈 필요없이 1-VAR 에서 구하시면 됩니다.)방법 (택1)
- 표준편차를 이용
$ \sigma_x = \sqrt{\frac{SSX}{n}} $ 이기 때문 - 수정항(CT) 를 이용하여 구할 수 있음.
S = ∑ vi2 = ∑ ( xi - x )2
= ∑ (xi2 - 2 xi x + x2 )
= ∑ xi2 - 2 x ∑ xi + n x2
= ∑ xi2 - 2 ( ∑ xi ) / n × ∑ xi + n ( ∑ xi / n )2
= ∑ xi2 - ( ∑ xi )2 / nhttp://q-engineering.pe.kr/6_1.htm
- 표준편차를 이용
-
1
세상의모든계산기
SSx 예제
http://kin.naver.com/qna/detail.nhn?d1id=11&dirId=1131&docId=288088531
- 【MODE】【3】【1】 : 1-VAR 모드로 진입
- DATA 입력

입력 마쳤으면 【AC】
- 【SHIFT】【1】【4】【3】
【x²】【×】【5】

(변량이 5개로 많지 않으므로, n을 찾아서 입력하기 보다 숫자로 대입하는 편이 좋겠습니다.)
- 【MODE】【3】【1】 : 1-VAR 모드로 진입
- 1
- 1
- 1
-
1
세상의모든계산기
제가 정확한 답변을 드릴 수 없어서 ChatGPT-4o 의 답변을 대신 달아드립니다.
편차의 제곱합(SSX)을 계산할 때 모표준편차를 사용하는 이유와 표본표준편차를 사용하는 이유는 통계 분석의 맥락에 따라 다릅니다.
1. **모표준편차와 모분산**:
- 모표준편차(\(\sigma\))는 전체 모집단의 분산과 표준편차를 계산할 때 사용됩니다.
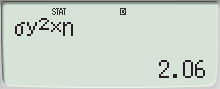
- 모표준편차를 사용할 때는 모집단의 모든 데이터를 알고 있는 경우에 해당하며, 모분산 \(\sigma^2\)를 이용하여 **SSX**를 계산할 수 있습니다:
\[
SSX = \sigma^2 \times n
\]
- 이 방법은 모집단 전체를 대상으로 하는 경우에 적용됩니다.2. **표본표준편차와 표본분산**:
- 표본표준편차(s)는 모집단의 일부인 표본에서 계산된 표준편차로, 표본의 데이터만 가지고 분석을 수행할 때 사용됩니다.
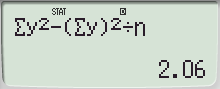
- 표본표준편차를 사용할 때는 표본의 분산을 구하는 데 필요하며, 표본의 분산 \(s^2\)를 사용하여 표본 데이터의 편차 제곱합을 계산할 수 있습니다:
\[
SSX = s^2 \times (n - 1)
\]
- 이 방법은 표본에서 모집단을 추정할 때 적합합니다.따라서, **모표준편차**를 사용하는 것은 모집단 전체를 대상으로 하는 경우이고, **표본표준편차**는 표본을 대상으로 하는 경우입니다. 분석의 맥락에 따라 적절한 값을 사용해야 합니다.
- 1
- 2
- 3
- 4
-
5
세상의모든계산기
현재 입력된 DATA Set
-----------------------------
DATA Set 으로 계산된 변량
1) 변량을 하나하나 확인하거나,
2) 변량을 이용해 계산을 하거나뭘 하더라도
이미 입력되어 있는 DATA Set 은 계속 남아 있습니다.따라서 현재 입력되어 있는 DATA는 언제라도 확인 가능합니다.
이미 입력된 DATA가 없어지는 것은,
1) 모드를 변경할 때
2) 리셋할 때 (Setup Data / Initialize All)
뿐입니다.
"계산기를 OFF 할 때 / 자동 OFF 될 때" 도 없어지는 줄 알았는데, fx-991EX 로 해보니 남아 있네요.
4단까지 댓글 가능 - 5
세상의모든계산기 님의 최근 댓글
해결 방법 1. t=-1 을 기준으로 그래프를 2개로 나누어 표현 ㄴ 근데 이것도 tstep을 맞추지 않으면 문제가 발생할 것기도 하고, 상관이 없을 것 같기도 하고... 모르겠네요. 2. t=-1 이 직접 계산되도록 tstep을 적절하게 조정 tstep=0.1 tstep=0.01 도 해 보고 싶지만, 구간 크기에 따라 최소 tstep 이 변하는지 여기서는 0.01로 설정해도 0.015로 바뀌어버립니다. 그래서 tstep=0.02 로 하는게 최대한 긴 그래프를 얻을 수 있습니다. 2026 02.02 불연속 그래프 ti-nspire는 수학자처럼 연속적인 선을 그리는 것이 아니라, 정해진 `tstep` 간격으로 점을 찍고 그 점들을 직선으로 연결하는 'connect-the-dots' 방식으로 그래프를 그립니다. 여기에 tstep 간격에 따라 특이점(분모=0)이 제외되어 문제가 나타난 것입니다. seq(−2+0.13*t,t,0,23) {−2.,−1.87,−1.74,−1.61,−1.48,−1.35,−1.22,−1.09,−0.96,−0.83,−0.7,−0.57,−0.44,−0.31,−0.18,−0.05,0.08,0.21,0.34,0.47,0.6,0.73,0.86,0.99} t=-1 에서 그래프를 찾지 않습니다. 그 좌우 값인 −1.09, −0.96 두 값의 그래프값을 찾고, Window 범위를 보고 적당히 (연속되도록) 이어서 그래프를 완성하는 방식입니다. 그래서 t=-1에서도 그래프 값이 존재하는 것입니다. 2026 02.02 조만간 있을 AGI의 '완성' 시점은 최종 형태가 아니라, 질적으로 다른 무언가가 '시작'되는 변곡점을 의미합니다. 그렇다면 그 변곡점의 본질, 즉 '초기 단계 AGI'와 그 직전의 '고도로 발전된 AI + 에이전트 시스템'의 근본적인 차이는 무엇일까요? 가장 큰 차이는 '주어진 목표를 수행하는 능력'에서 '스스로 목표를 설정하고 추상적인 의도를 이해하는 능력'으로의 전환입니다. 조금 더 구체적으로, 다음과 같은 4가지 근본적인 차이점으로 설명할 수 있습니다. --- 1. 자율적 목표 설정 및 재정의 능력 (Autonomous Goal Setting) * 이전 (AI + 에이전트): 인간이 명확한 목표를 '제시'해야 합니다. * "대한민국의 저출산 문제에 대한 원인과 해결책을 조사해서 100페이지 분량의 보고서로 만들어 줘." -> 이 목표는 복잡하지만 명확합니다. AI는 이 목표를 달성하기 위해 인터넷을 검색하고, 데이터를 분석하고, 문서를 작성하는 등 수많은 하위 작업을 수행합니다. 하지만 '보고서 작성'이라는 최종 목표 자체를 바꾸지는 않습니다. * 이후 (초기 AGI): 인간이 추상적인 '의도'나 '상태'를 제시하면, 스스로 최적의 목표를 '설정'하고, 상황에 따라 목표를 수정합니다. * "대한민국의 저출산 문제를 해결해 줘." -> AGI는 '해결'이라는 단어의 의미를 스스로 정의하기 시작합니다. 1. 단기 목표: '온라인상의 부정적인 여론을 긍정적으로 전환'이라는 목표 설정 -> 여론 조작이 아닌, 긍정적 정책 홍보 캠페인 기획 및 실행. 2. 중기 목표: '가장 효율적인 양육비 지원 정책 모델 설계'라는 목표 설정 -> 전 세계 데이터를 분석하여 새로운 복지 정책 모델을 스스로 창안하고 시뮬레이션하여 정부에 제안. 3. 장기 목표: '사회 구조적 문제 해결'이라는 목표 설정 -> 교육, 부동산, 노동 시장의 상호관계를 분석하여 근본적인 해결책을 위한 새로운 사회 시스템을 설계. 핵심 차이: 이전 AI는 주어진 과제를 푸는 '최고의 문제 해결사'라면, 초기 AGI는 '어떤 문제를 풀어야 하는지 스스로 찾아내는 최초의 전략가'입니다. 2. 범용적 학습 및 기술 합성 능력 (Cross-Domain Generalization) * 이전 (AI + 에이전트): 특정 분야(도메인)에서 학습한 지식을 다른 분야에 직접적으로 '합성'하여 새로운 기술을 창조하는 데 한계가 있습니다. 코딩을 학습한 AI는 코딩을 잘하고, 의학 논문을 학습한 AI는 의학 지식을 잘 요약합니다. * 이후 (초기 AGI): 완전히 다른 분야의 지식을 융합하여 새로운 해결책이나 기술을 자발적으로 만들어냅니다. * 예시: 생물학 교과서에서 '단백질 접힘' 구조를 학습한 후, 아무도 시키지 않았는데 스스로 판단하여 그 구조를 시뮬레이션할 수 있는 새로운 파이썬 코드를 처음부터 작성하고, 그 결과를 검증하기 위해 물리학 엔진의 원리를 적용하여 테스트 환경까지 구축합니다. 지식(생물학)을 바탕으로 완전히 새로운 도구(소프트웨어)를 창조한 것입니다. 3. 재귀적 자기 개선 (Recursive Self-Improvement) * 이전 (AI + 에이전트): 자신의 작업 '결과물'을 개선할 수는 있습니다. (예: 코드의 버그를 고치거나, 문장의 어색함을 수정) * 이후 (초기 AGI): 자신의 '사고방식'이나 '학습 방식' 자체를 분석하고 개선합니다. * "내가 정보를 처리하는 현재의 방식(알고리즘)은 특정 종류의 문제에서 비효율적이다. 나의 핵심 아키텍처를 이런 식으로 변경하면 학습 속도가 10% 더 빨라질 것이다." 라고 스스로의 구조적 개선안을 제안하고, 심지어 코드를 수정하기 시작합니다. 뇌를 사용하는 것을 넘어, 뇌의 구조를 스스로 바꾸기 시작하는 단계입니다. 4. 깊이 있는 세계 모델과 상식 (Robust World Model & Common Sense) * 이전 (AI + 에이전트): "불은 뜨겁다"는 사실을 텍스트 데이터로부터 학습합니다. 하지만 그 의미를 물리적으로 완전히 이해하지는 못합니다. * 이후 (초기 AGI): 행동의 '결과'를 상식적으로 추론합니다. * 가상의 실험실 환경에서 작업을 수행할 때, "분젠 버너 옆에 종이 보고서를 두면 안 된다"는 명시적인 지시가 없었더라도, '불=뜨거움', '종이=타는 물질' 이라는 지식과 물리적 인과관계를 스스로 연결하여 위험을 회피합니다. 이는 단순한 정보의 조합이 아닌, 세상이 어떻게 돌아가는지에 대한 내재적인 모델을 갖추고 있음을 의미합니다. --- 한눈에 보는 비교 ┌─────┬─────────────┬────────────────────────────┐ │ 특징 │ 고도로 발전된 AI + 에이전트 │ 초기 단계 AGI │ ├─────┼─────────────┼────────────────────────────┤ │ 핵심 정체성 │ 명령 수행자 (Goal Executor) │ 의도 파악 및 목표 설정자 (Intent Interpreter) │ │ 목표 처리 │ 주어진 구체적 목표를 완벽하게 수행 │ 추상적 의도를 바탕으로 스스로 목표 설정/수정 │ │ 학습/기술 │ 특정 분야에 특화, 도구 사용에 능숙 │ 여러 분야의 지식을 융합하여 새로운 기술 창조 │ │ 자기 개선 │ 결과물(Output)을 수정 │ 사고방식/구조(Process/Architecture)를 수정 │ │ 추론 방식 │ 논리, 데이터 기반 추론 │ 상식과 인과관계 기반의 추론 │ └─────┴─────────────┴────────────────────────────┘ 결론적으로, 2027~2030년에 우리가 목격할 '초기 AGI'는 단순히 더 똑똑해진 AI가 아니라, 인간의 지시 없이도 스스로 '왜?'라고 질문하고, 자신만의 목표를 만들어 행동하며, 스스로를 성장시키는 질적으로 완전히 다른 존재의 첫 등장을 의미할 것입니다. 2026 01.31 > 자동차 회사의 노조가 "노조와 합의 없이 AI로봇을 공장에 들일 수 없다"는 선언을 하고 있어. 위의 내용에 적용하여 해결 방안을 만들어 줘. ✦ 네, 아주 현실적이고 시의적절한 시나리오입니다. 자동차 회사의 노조 선언은 앞으로 여러 산업 현장에서 벌어질 일의 축소판과도 같습니다. 이 문제를 앞서 나눈 대화의 해결 방안에 적용하여, '기업-노조-정부' 3자가 참여하는 '미래 지향적 대타협: AI 전환 파트너십 구축 방안'을 구체적으로 만들어 보겠습니다. 상황 분석: 노조의 선언은 '저항'이 아닌 '협상 요구' 먼저, 노조의 선언을 "기술을 맹목적으로 거부하는 러다이트 운동"으로 해석해서는 안 됩니다. 이는 일자리의 미래와 인간의 존엄성에 대한 조합원들의 지극히 합리적인 '불안'의 표현이자, 변화의 과정에서 소외되지 않고 주체적으로 참여하겠다는 강력한 '협상 요구'입니다. 따라서 해결 방안의 목표는 노조를 억누르는 것이 아니라, 이들을 AI 전환의 가장 중요한 '파트너'로 만드는 것이어야 합니다. 해결 방안: 'AI 전환 파트너십' 3자 협약 모델 이 모델은 '사회적 안전망'과 '산업적 가속 페달'의 원리를 특정 산업 현장에 맞게 구체화한 것입니다. 1. 기업의 역할: '이익 공유'와 '재교육 투자'를 통한 신뢰 구축 기업은 AI 로봇 도입으로 얻게 될 막대한 이익을 독점하는 대신, 그 과실을 노동자들과 공유하고 이들의 미래에 투자하는 모습을 보여주어야 합니다. ① 생산성 향상 이익 공유제 도입: * AI 로봇 도입으로 발생하는 비용 절감액과 생산성 향상분의 일정 비율(예: 20%)을 노사 합의로 'AI 전환 기금'으로 적립합니다. 이 기금은 아래의 재교육 및 전환 배치 프로그램의 재원으로 사용됩니다. ② 대규모 사내 재교육 및 '신(新)직무' 전환 배치: * 단순 조립 라인의 노동자를 해고하는 대신, 이들을 새로운 시대에 필요한 인력으로 재교육하여 전환 배치합니다. 이것이 바로 '기여 인센티브' 개념을 기업 내에서 실현하는 것입니다. * '로봇 유지보수 및 운영 전문가': 현장 경험이 풍부한 노동자들이 로봇의 일상적인 점검, 유지보수, 운영을 책임집니다. * 'AI 시스템 모니터링 및 평가자': 로봇의 생산 데이터를 모니터링하고, 로봇의 움직임이나 작업 결과가 비정상적일 때 이를 식별하고 평가하는 역할을 합니다. (예: "이 로봇의 용접 불량률이 높아지고 있다.") * '공정 데이터 라벨러 및 AI 트레이너': 숙련된 인간 노동자의 정교한 움직임과 문제 해결 과정을 데이터로 기록하고, 이를 AI가 학습할 수 있도록 가공(라벨링)합니다. 이는 AI 로봇의 완성도를 높이는 가장 중요한 '데이터 노동'이며, 기존 노동자들에게 새로운 고부가가치 직무를 제공합니다. 2. 노조의 역할: '저항의 주체'에서 '전환의 주체'로 노조는 고용 안정을 보장받는 대신, AI 도입에 협력하며 조합원들이 새로운 시대에 적응하도록 이끄는 역할을 맡습니다. ① 단계적 AI 도입 협력: * 회사가 제안한 '이익 공유' 및 '재교육' 계획을 신뢰하고, AI 로봇 도입 자체에 대한 반대를 철회합니다. 대신, 가장 위험하거나 반복적인 공정부터 로봇을 도입하는 '단계적 계획'을 회사와 함께 수립합니다. ② 재교육 프로그램 공동 설계 및 운영: * 회사가 제공하는 재교육 프로그램이 실효성이 있는지 감시하고, 현장 노동자들의 눈높이에 맞게 커리큘럼을 공동으로 설계하고 운영합니다. ③ '신(新)직무'에 대한 임금 및 단체 협약 체결: * 'AI 트레이너', '로봇 운영 전문가' 등 새롭게 만들어진 직무에 대한 적정한 임금 수준, 노동 조건, 권익 보호를 위한 새로운 단체 협약을 회사와 체결합니다. 노조의 역할이 '기존 일자리 사수'에서 '미래 일자리의 가치 창출 및 권익 보호'로 진화하는 것입니다. 3. 정부의 역할: '안전망' 제공과 '가속 페달' 지원 정부는 이 대타협이 원활하게 이루어지도록, 기업과 노조 양측 모두에게 인센티브를 제공하고 최후의 안전망을 구축합니다. ① 'AI 전환 투자 세제 혜택' 제공 (가속 페달): * 회사가 'AI 전환 기금'에 출연하는 금액과, 노동자 재교육에 투자하는 비용에 대해 파격적인 세액 공제 혜택을 줍니다. 이는 회사가 노동자를 해고하는 대신 재교육을 선택하도록 유도하는 강력한 당근이 됩니다. ② '전환기 고용보험' 적용 (안전망): * 불가피하게 전환 배치되지 못하는 소수의 노동자들을 위해, 일반 실업급여보다 더 긴 기간 동안, 더 높은 수준의 소득을 보장하는 특별 고용보험 프로그램을 적용합니다. 재취업 및 창업 지원도 병행합니다. ③ 국가적 '기본소득/기여 인센티브' 모델의 시범 사업으로 지정: * 이 자동차 공장의 사례를 국가 전체의 사회 시스템 전환을 위한 중요한 시범 사업으로 지정하고, 재교육 참여자나 신직무 종사자에게 국가 차원의 '기여 인센티브'를 추가로 제공하는 방안을 모색합니다. 결론 이러한 3자 파트너십을 통해, 노조의 선언은 더 이상 '위기'가 아닌 '기회'가 됩니다. 기업은 노사 갈등 없이 안정적으로 미래 경쟁력을 확보하고, 노동자들은 일자리를 잃는 대신 새로운 기술 시대의 주역으로 거듭나며, 정부는 사회적 혼란을 최소화하며 산업 구조 전환을 성공적으로 이끌 수 있습니다. 이는 AI 시대의 갈등을 해결하는 가장 현실적이고 상생 가능한 모델이 될 것입니다. 2026 01.28 은행앱 통합하면서 없어졌나보네요. ㄴ 비슷한 기능 찾으시는 분은 : 스마트 금융 계산기 검색해 보세요. https://play.google.com/store/apps/details?id=com.moneta.android.monetacalculator 2026 01.25