
- CASIO 공통
[fx-570][fx-350] STAT 통계 모드 진행 과정 (변수 분석, 회귀 분석 등 전반)
-

- 2025.09.23 - 14:40 2015.03.12 - 09:47 34024 21
1. 통계 변수 분석 (STAT) 모드란?
통계 계산 모드는 통계 데이터를 입력하는 것만으로, 각종 통계 결과를 쉽게 확인할 수 있는 모드입니다.
(350이나 570 등의) 기초형 계산기에서는 아주 기본적인 통계변수의 결과만 찾아줍니다.
* 국내 ES PLUS 계열에는 분포Distribution 기능이 빠져 있으니,
통계 목적으로는 fx-570EX 급을 구입하시는게 좋겠습니다. 결과 확인도 훨씬 수월합니다. fx-570 CW 도 비슷합니다.
(그래핑 계산기급 이상의) 고급형 계산기에서는 Graph / Plot / Datagram 등을 그려주는 기능이 있습니다.
2. 주의사항
- [fx-350]기종과 [fx-570]기종은 STAT 모드 진입 버튼이 다릅니다. 진입 후에는 차이가 없습니다.
예) 1-VAR(1변수분석)
[fx-570ES]는 【MODE】【3】【1】
[fx-570EX]는 【MENU】【6】【1】
[fx-350ES]는 【MODE】【2】【1】
이하, 본문은 [fx-570ES] 기종을 기준으로 설명되어 있으므로 감안하고 읽으시기 바랍니다.
- 모드가 변경되면 이미 입력한 데이터 값이 '초기화'될 수가 있습니다. 따라서 모드 변경시 주의하셔야 합니다.
예를 들어 【MODE】【3】【2】 로 선형회귀 결과를 확인하다가, 동일한 데이터로 다른 타입에 속하는 지수회귀 결과를 보려고 할 때, 【MODE】【3】【6】 을 누르면 선형회귀에서 입력해놓은 데이터가 다 날아갑니다. 따라서 【AC】 누른 후에 【SHIFT】【1】【1】 을 눌러서 STAT 모드 내부에서 Type만을 변경하여야 합니다.
- [MS] 기종은 [ES] 기종과 사용 방법이 약간 다를 수 있습니다. [EX] 기종도 마찬가지구요.
https://allcalc.org/8114
본문은 [ES] 기종을 기준으로 설명되어 있습니다.
3. 계산 진행 과정 (입력 순서)
계산기의 통계 모드는 처음 사용할 때 굉장히 복잡해 보일 수 있는데, 핵심과정만 구분할 수 있으면 하나도 어렵지 않습니다.
- TYPE 결정 【SHIFT】【1】 【1】
여러 통계 모드 중에서 어떤 (Type의) 기능을 사용할지 결정
https://allcalc.org/6167
* Type 은 통계 계산 과정 중 언제라도 변경할 수 있습니다. 이 때 DATA를 초기화할지 결정할 수 있습니다.
- DATA 입력/수정/확인【SHIFT】【1】 【2】
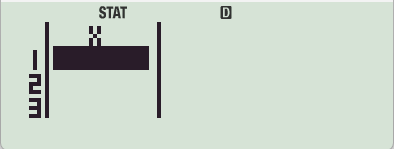
데이터를 입력하고 수정합니다.
입력한 데이터는 통계(STAT)모드 내에서 언제라도 수정 가능합니다.
모드 변경으로만 넘어가지 않으면 입력해 둔 DATA값이 초기화되지 않습니다.
- 결과 확인
【AC】 를 눌러서 통계 DATA 입력모드에서 나옵니다.
【SHIFT】【1】 을 눌러서 (Sum, Var 등의) 통계 변수값을 확인합니다.
(EX 기종은 【OPTN】 을 눌러서 통계 변수값을 확인합니다.)
4. 통계 분석 결과 (사용가능한 변수)
| Sum |
|
| Var |
|
| Reg |
|
※ 통계 모드에 따라 사용 가능한 변수 종류가 달라집니다.
-
25
댓글21
-
세상의모든계산기
예시 : 1-VAR(1변수 분석) [fx-570ES]
- 문제 : 데이터가 {1, 2, 3, 4, 5, 6} 일 때, 표본 표준편차를 구한다.
- 계산기 입력 :
【MODE】【3】【1】 : 1-VAR, DATA 입력 화면으로 이동
【1】【=】【2】【=】【중간생략】【6】【=】 : DATA 입력 완료
【AC】 : STAT 기본 화면으로 이동
【SHIFT】【1】【4】 Var : 원하는 통계 변수 선택 (문제에서는 표본의 표준편차)
【4】【=】 : sx (표본표준편차) 선택
- 결과의 확인
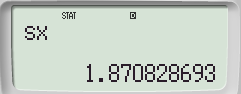
- 모표준편차와 표본표준편차를 구분하여 사용합니다.
- ∑x 나 ∑x² 와 같은 변수는 【SHIFT】【1】【3】 Sum 항목에서 찾아볼 수 있습니다.
- 문제 : 데이터가 {1, 2, 3, 4, 5, 6} 일 때, 표본 표준편차를 구한다.
-
세상의모든계산기
편차 제곱합(SSy) 구하는 방법
문제
회귀(REG) 계산에서 DATA를 입력하고,
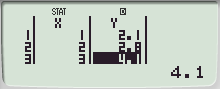
y의 편차 제곱합 = ∑((yi-y바)²) 을 구하려 함.
(1 변수 DATA 라면 REG 모드로 갈 필요없이 1-VAR 에서 구하시면 됩니다.)방법 (택1)
- 표준편차를 이용
$ \sigma_x = \sqrt{\frac{SSX}{n}} $ 이기 때문 - 수정항(CT) 를 이용하여 구할 수 있음.
S = ∑ vi2 = ∑ ( xi - x )2
= ∑ (xi2 - 2 xi x + x2 )
= ∑ xi2 - 2 x ∑ xi + n x2
= ∑ xi2 - 2 ( ∑ xi ) / n × ∑ xi + n ( ∑ xi / n )2
= ∑ xi2 - ( ∑ xi )2 / nhttp://q-engineering.pe.kr/6_1.htm
- 표준편차를 이용
-
1
세상의모든계산기
SSx 예제
http://kin.naver.com/qna/detail.nhn?d1id=11&dirId=1131&docId=288088531
- 【MODE】【3】【1】 : 1-VAR 모드로 진입
- DATA 입력

입력 마쳤으면 【AC】
- 【SHIFT】【1】【4】【3】
【x²】【×】【5】

(변량이 5개로 많지 않으므로, n을 찾아서 입력하기 보다 숫자로 대입하는 편이 좋겠습니다.)
- 【MODE】【3】【1】 : 1-VAR 모드로 진입
- 1
- 1
- 1
-
1
세상의모든계산기
제가 정확한 답변을 드릴 수 없어서 ChatGPT-4o 의 답변을 대신 달아드립니다.
편차의 제곱합(SSX)을 계산할 때 모표준편차를 사용하는 이유와 표본표준편차를 사용하는 이유는 통계 분석의 맥락에 따라 다릅니다.
1. **모표준편차와 모분산**:
- 모표준편차(\(\sigma\))는 전체 모집단의 분산과 표준편차를 계산할 때 사용됩니다.
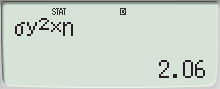
- 모표준편차를 사용할 때는 모집단의 모든 데이터를 알고 있는 경우에 해당하며, 모분산 \(\sigma^2\)를 이용하여 **SSX**를 계산할 수 있습니다:
\[
SSX = \sigma^2 \times n
\]
- 이 방법은 모집단 전체를 대상으로 하는 경우에 적용됩니다.2. **표본표준편차와 표본분산**:
- 표본표준편차(s)는 모집단의 일부인 표본에서 계산된 표준편차로, 표본의 데이터만 가지고 분석을 수행할 때 사용됩니다.
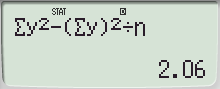
- 표본표준편차를 사용할 때는 표본의 분산을 구하는 데 필요하며, 표본의 분산 \(s^2\)를 사용하여 표본 데이터의 편차 제곱합을 계산할 수 있습니다:
\[
SSX = s^2 \times (n - 1)
\]
- 이 방법은 표본에서 모집단을 추정할 때 적합합니다.따라서, **모표준편차**를 사용하는 것은 모집단 전체를 대상으로 하는 경우이고, **표본표준편차**는 표본을 대상으로 하는 경우입니다. 분석의 맥락에 따라 적절한 값을 사용해야 합니다.
- 1
- 2
- 3
- 4
-
5
세상의모든계산기
현재 입력된 DATA Set
-----------------------------
DATA Set 으로 계산된 변량
1) 변량을 하나하나 확인하거나,
2) 변량을 이용해 계산을 하거나뭘 하더라도
이미 입력되어 있는 DATA Set 은 계속 남아 있습니다.따라서 현재 입력되어 있는 DATA는 언제라도 확인 가능합니다.
이미 입력된 DATA가 없어지는 것은,
1) 모드를 변경할 때
2) 리셋할 때 (Setup Data / Initialize All)
뿐입니다.
"계산기를 OFF 할 때 / 자동 OFF 될 때" 도 없어지는 줄 알았는데, fx-991EX 로 해보니 남아 있네요.
4단까지 댓글 가능 - 5
세상의모든계산기 님의 최근 댓글
불러오기 할 때 변수값을 먼저 확인하고 싶을 때는 VARIABLE 버튼 【⇄[x]】목록에서 확인하고 Recall 하시면 되고, 변수값을 이미 알고 있을 때는 바로 【⬆️SHIFT】【4】로 (A)를 바로 입력할 수 있습니다. 2025 10.24 fx-570 CW 로 계산하면? - 최종 확인된 결과 값 = 73.049507058478629343538 (23-digits) - 오차 = 6.632809104889414877 × 10^-19 꽤 정밀하게 나온건 맞는데, 시뮬레이션상의 22-digits 와 오차 수준이 비슷함. 왜 그런지는 모르겠음. - 계산기중 정밀도가 높은 편인 HP Prime CAS모드와 비교해도 월등한 정밀도 값을 가짐. 2025 10.24 HP Prime 에서 <Home> 73.0495070344 (12-decimal-digits) // python 시뮬레이션과 일치 <CAS> 21자리까지 나와서 이상하다 싶었는데, Ans- 에서 자릿수를 더 늘려서 빼보니, 뒷부분 숫자가 아예 바뀌어버림. 버그인가? (전) 73.0495070584718691243 (21-digits ????) (후) 73.0495070584718500814401 (24-digits ????) 찾아보니 버그는 아니고, CAS에서는 십진수가 아니라 2진수(bit) 단위로 처리한다고 함. Giac uses 48 bits mantissa from the 53 bits from IEEE double. The reason is that Giac stores CAS data (gen type) in 64 bits and 5 bits are used for the data type (24 types are available). We therefore loose 5 bits (the 5 low bits are reset to 0 when a double is retrieved from a gen). 출처 : https://www.hpmuseum.org/cgi-bin/archv021.cgi?read=255657 일단 오차를 놓고 보면 16-decimal-digits 수준으로 보임. 2025 10.23 khiCAS 에서 HP 39gII 에 올린 khiCAS는 254! 까지 계산 가능, 255! 부터는 ∞ fx-9750GIII 에 올린 khiCAS는 factorial(533) => 425760136423128437▷ // 정답, 10진수 1224자리 factorial(534) => Object too large 2025 10.23 같은 방식으로 500! 근사값을 구해보면 1.219933487 × 10^(1134) 1.22013682599111006870123878542304692625357434280319284219241358838 × 10^(1134) (참값, 울프람 알파) 2025 10.23