
- 세상의 모든 계산기 자유(질문) 게시판 일반 ()
알파고에 사용된 것은 GPU 가 아니라 TPU?
-

- 2017.04.11 - 15:57 2016.05.23 - 14:16 4002 5
출처 : https://cloudplatform.googleblog.com/2016/05/Google-supercharges-machine-learning-tasks-with-custom-chip.html
 |
| Tensor Processing Unit board |
 |
| Server racks with TPUs used in the AlphaGo matches with Lee Sedol |
- 이세돌과의 대국에서 승리를 확정했던 3국의 기보가 붙어있네요. (4국이었다면 좀 더 인간적?이었을 것 같기도 하고...)
- 기존에 알려졌던 것과 달리, 알파고 AI(Tensorflow) 구현에 있어 GPU(범용 칩)이 아닌 주문형 반도체인 ASIC 칩을 사용한 것 같습니다. (이건 확실치 않습니다)
- 그림상 하나의 M/B 에 4개의 검정 케이블이 바로 TPU와 M/B 를 연결하기 위한 PCIE extension 케이블인 것으로 보입니다.
- 사진상으로는 개별 머쉰이 총 (6*8)-2 = 46 개입니다.
46*4 = 184 인데... 기존에 176개 GPU가 사용되었다고 알려진 것을 생각하면 얼추 맞는 것 같긴 하네요. - 사용된 CPU 갯수도 (기존에 추정되었던 개별 CPU 단위가 아니라) 코어(혹은 쓰레드) 단위일 가능성이 높아 보입니다.
46*12C=552C, 46*24T=1104T. (듀얼이라면, 2208T인데 1920과 얼추 맞는 것 같습니다. 1920=24*2*40)
참고 링크
- http://www.recode.net/2016/5/20/11719392/google-ai-chip-tpu-questions-answers
-
25
댓글5
-
세상의모든계산기
월 스트리트 저널 기사 - 링크 : http://www.wsj.com/articles/google-isnt-playing-games-with-new-chip-1463597820 를 읽어보니 GPU 가 이닌 ASIC을 사용한 것이 확실해 보이네요.
When Google’s AlphaGo computer program bested South Korean Go champion Lee Se-dol in March, it took advantage of a secret weapon: a microprocessor chip specially designed by Google.
기사에 따르면 다른 대안(아마도 GPU)보다 전반적으로 10배 빠른 계산이 가능했다는 것 같습니다. (기사에는 MS 도 AI 분야에 FPGA 칩을 사용한다고 합니다. IBM 도 전용 칩을 쓴다고 하구요. 아범이야 뭐 당연한거지만...)
-
세상의모든계산기
구글 직원(Solutions Engineer for Google Cloud Platform at Google. Co-organizer @codemotion_es)의 트윗
https://twitter.com/nachocoloma/status/733169977432395776
이로서 확실해졌네요. GPU 는 사용되지 않았습니다. 대신 더 뛰어난 TPU 가 사용되었습니다.
(당분간!) 범용 PC 구성(CPU+GPU)으로 알파고 수준에 도달하기는 쉽지 않겠습니다. 하물며 CPU 만 사용하는 상용 바둑 프로그램으로는...
-
세상의모든계산기
TPU의 전성비
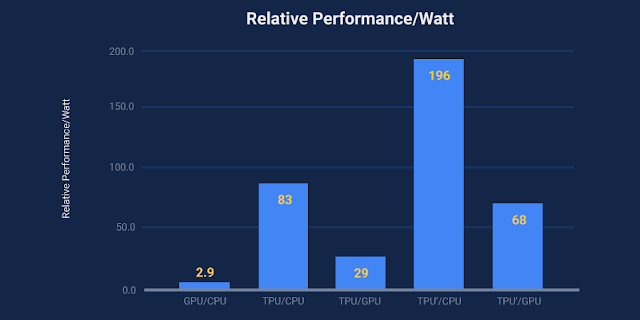
출처 : https://cloudplatform.googleblog.com/2017/04/quantifying-the-performance-of-the-TPU-our-first-machine-learning-chip.html
Quantifying the performance of the TPU, our first machine learning chip
Wednesday, April 5, 2017
By Norm Jouppi, Distinguished Hardware Engineer, Google
(503 에러때문에 못본다면 블로그에서 날짜로 찾아보세요)
세상의모든계산기 님의 최근 댓글
- claude AI는 l-c*r^2 을 1-c*r^2 으로 잘못 읽고 표시하고 있습니다. - TI-nspire CAS 계산기에 l-c*r^2 ≥0 을 조건에 추가해 계산해 보아도 결과는 바뀌지 않습니다. 2026 07.20 ⚠️ 경고가 바로 두 번째 방법이 "성공"한 이유와 정확히 연결되어 있습니다. 경고의 의미 "Domain of the result might be larger than the domain of the input"는 CAS가 절댓값(모듈러스)을 계산하는 과정에서 원래 식보다 정의역이 더 넓은 형태로 단순화했다는 뜻입니다. 구체적으로 이 계산은 내부적으로 대략 이런 과정을 거칩니다. $$\left|\frac{er}{e\cdot r}\right| = \sqrt{\left(\frac{er}{e\cdot r}\right)\cdot\overline{\left(\frac{er}{e\cdot r}\right)}}$$ 즉 원래 식(복소수)과 그 켤레복소수를 곱해서 실수부·허수부 제곱합을 만들고, 거기에 다시 제곱근을 씌우는 과정입니다. 이 과정에서 √(x²) → x 또는 √a·√b → √(ab) 같은 규칙들이 쓰이는데, 이런 규칙들은 x가 실수이고 0 이상일 때만 엄밀하게 성립합니다. CAS는 이 조건들을 일일이 다 추적하지 않고 넘어가면서, 원래는 (e≠0, r+l·ω·i ≠ 0 등) 복소수 특유의 좁은 정의역을 가진 식을, r, l, ω가 어떤 실수여도(부호 무관하게) 정의되는 1/√(r²+l²·ω²)라는 더 넓은 정의역의 식으로 바꿔버린 것입니다. CAS는 이 손실을 감지하고 경고를 띄운 것입니다. 이게 왜 조건 대입 성공과 연결되는가 정리하면, 이 경고는 사실상 이런 뜻입니다. "나는 이 결과를 만들면서 원래 식이 가지고 있던 정의역 제약 정보(부호 조건, i 관련 조건 등)를 이미 버렸다." 바로 이 "정의역 정보를 버린" 상태가 이후 con_1 대입을 매끄럽게 만드는 원인입니다. 첫 번째 시도에서는 i가 살아있는 원래 식에 조건을 대입했기 때문에, CAS가 √(1-c·r²)이 실수인지(정의역 조건: 1-c·r² ≥ 0) 계속 추적하려고 했고, 그 정보가 con에 없어서 더 이상 정리를 못 하고 멈췄습니다. 두 번째 시도에서는 절댓값 계산 단계에서 이미 그런 세밀한 정의역 추적을 CAS 스스로 포기(단순화)했기 때문에, 이후 ω에 무리식을 대입해도 "이게 실수가 맞나?" 하는 검증 절차 없이 그냥 대수적으로 치환·정리해 버립니다. 그래서 깔끔하게 √c/√l이 나온 겁니다. 한 줄 요약 절댓값 계산 시 뜬 "정의역이 넓어졌을 수 있다"는 경고는, CAS가 그 순간에 원래 식의 엄밀한 조건(정의역)을 놓쳤다는 신호이고, 바로 그 "조건을 놓친 상태"이기 때문에 뒤에 이어지는 조건식 대입이 막힘없이 진행된 것입니다. 다만 그 대가로, 결과인 1/√(r²+l²·ω²)이나 최종 √c/√l이 원래 회로 조건(i≠0이 되는 경계, 분모가 0이 되는 경우 등)에서는 엄밀히 성립하지 않을 수 있다는 점은 감안하셔야 합니다. 실제 물리적으로는 r, l, c > 0이고 결과도 물리적으로 타당한 형태라 문제없어 보이지만, 수학적 엄밀성 측면에서는 "정의역이 넓어진 근사적 결과"라는 꼬리표가 붙어있는 셈입니다. 2026 07.20 Claude AI 답변 TI-Nspire CAS의 | (such that / 조건대입) 연산자는 대입 시점의 수식 형태를 그대로 두고 기호만 치환하는 연산입니다. 대입 후에 처음부터 다시 "실수부/허수부 분리, 유리화" 같은 재간소화를 자동으로 수행하지 않습니다. 이 차이가 지금 보신 결과 차이의 핵심입니다. 첫 번째 경우 (|er/(e·r)| | con_1 and con → 실패) 이 시점의 식은 아직 r + l·ω·i 형태의 복소수 그대로입니다 (i가 살아있음). 여기에 con_1: ω = √(1-c·r²)/(√c·l)을 대입하면, 분모 안에 i · √(1-c·r²) 라는 항이 새로 생깁니다. 문제는 CAS가 √(1-c·r²)이 실수인지(즉 1-c·r² ≥ 0인지) 판단할 근거가 없다는 겁니다. 저장해 두신 con 조건은 c>0, l>0, r>0뿐이고, 1-c·r²≥0이라는 조건은 포함되어 있지 않습니다. 그래서 CAS는 i와 이 무리식을 더 정리(유리화, 실수부·허수부 재결합)하지 못하고 있는 그대로 남겨둡니다. 결과에 여전히 i가 보이는 이유입니다. 두 번째 경우 (결과값 1/√(r²+l²·ω²)에 대입 → 성공) |er/(e·r)| (절댓값/모듈러스) 연산은 그 자체로 이미 "복소수 → 실수" 변환을 완료한 결과입니다. 즉 1/√(r²+l²·ω²)에는 더 이상 i가 없고, 순수하게 r, l, ω로만 이루어진 실수식입니다. 이 식에 ω = con_1을 대입하는 것은 그냥 실수 대수식에 실수 대입하는 것이므로, i와 무리식이 뒤엉키는 문제 자체가 발생하지 않습니다. 그래서 바로 깔끔하게 √c/√l로 정리됩니다. 정리하면 절댓값(모듈러스) 계산은 "이 값들이 실수다"라는 가정을 이미 내부적으로 써서 i를 제거하는 연산입니다. 그 연산을 조건 대입 이전에 해두면, 이후 대입은 단순 실수 대입이라 문제없이 정리됩니다. 반대로 i가 남아있는 식에 무리식을 포함한 조건을 먼저 대입하면, 그 무리식의 실수성/부호에 대한 가정이 없어서 CAS가 i를 소거하는 재간소화를 못 하고 멈춰버립니다. 실용적 팁: 복소식에 조건을 대입해야 할 때는 가능하면 절댓값·실수화(유리화) 등을 먼저 끝내서 i를 없앤 뒤 조건을 대입하거나, 대입 후 결과에 다시 simplify/expand/combine 같은 명령을 한 번 더 걸어주면 (필요한 도메인 조건과 함께) 정리가 되는 경우가 많습니다. 2026 07.19 저도 어림잡아 추측할 뿐이지 정확한 이유를 알지는 못합니다. 질문하신 사진을 그대로 (Gemini 3.5 Flash / ChatGPT / Claude Sonnet 5) AI에 넣어 보니 claude AI 가 제일 합리적인 답변을 주어서 이를 붙여 넣습니다. 2026 07.19 아 그렇네요. 감사합니다. ^^ 2026 04.28