
[공학용 계산기] 계산기 내부에서 사용하는 유효숫자 자릿수 Significant Digits
-

- 2024.10.30 - 19:09 2015.10.22 - 19:05 6861 8
1. 공학용 계산기에서 유효자릿수(Significant Digits)란?
과학적 실험 등에서 일반적으로 사용되는 개념으로서 "유효 숫자(Significant figures)" 라는 것이 있습니다.
계산기에도 "유효 숫자 (Significant Digits)"라는 유사한 용어가 있습니다만, 앞서 설명한 과학적(또는 수학적) 용어로서의 유효 숫자와는 개념이 다릅니다.
한글로 표현되는 이름만 같고 다른 용어라고 생각하시는게 좋습니다.
계산기에서는 어떠한 숫자(또는 계산 결과)가 정확한 값(Exact Number)과 구별되는 근사값(Approx Number)으로 인식될 때, 최대의 유효한 자릿수(10개~15개, 계산기마다 다름)만 남고, 나머지는 버려집니다.
내부 자릿수가 늘어날수록 정밀도(precision)는 높아집니다.
이 유효한 자릿수는 고정된 최대 자릿수만 있을 뿐이어서, 과학분야에서처럼 수식 내에서 가장 작은 유효 자릿수를 따라간다거나 하지는 않습니다.
2. 계산기 유효숫자 예시
예시 1)
1.9*10^27 + 5 = ?
참 값 = 1900000000000000000000000005 (정수)
이 값은 과학적 표기로 바꾸면 1.900000000000000000000000005 × (10^27) 입니다.
(1에서부터 마지막 5까지 정수 자릿수 27자리)
이 값은 유효숫자가 계산기가 허용하는 최대 자릿수보다 크기 때문에, (꼬리가 짤린) 1.9000000000000 × (10^27) 만 계산기의 메모리에 저장됩니다.
- 저장되는 유효숫자의 갯수는 계산기마다 다릅니다.
-
 정수(exact integer)와 소수(부동소숫점)의 유효자릿수가 다른 계산기도 있습니다. ([TI-nspire] 등)
정수(exact integer)와 소수(부동소숫점)의 유효자릿수가 다른 계산기도 있습니다. ([TI-nspire] 등)
예시 2)
(1.9×10^(-27)) + 5 = ?
참값은 5.0000000000000000000000000019 이지만, 최대 자릿수 제한으로 (꼬리가 짤린) 5.0000000000000 정도만 메모리에 저장이 됩니다.
예시 3)
(1.9 × 10^27 +5 ) - (1.9 × 10^27) = ?
당연히 5가 답으로 나와야 하지만, 실제로는 0이 나오게 됩니다.
수식의 계산 순서를 바꾸면 다시 5가 나오기도 하구요.
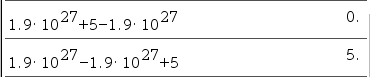
└ [TI-nspire]
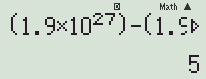
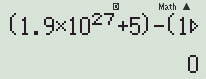
└ [fx-570 ES]
3. (부동)소숫점과 정수의 차이
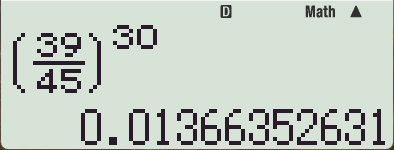
이렇게 긴 정수간의 분수 계산이 (부동)소숫점 형태로 나오는게 일반적이지만,

이렇게 internal significant digits 와 별개로 긴 자릿수까지 저장할 수도 있습니다.
CAS급의 최고급형 계산기에서만 그렇습니다.
-
25
댓글8
-
세상의모든계산기
샤프 계산기 사용 설명서 일부

Internal calculations: Mantissas of up to 14 digits
-
세상의모든계산기
TI-89 답변 중 발췌
"Internally, the device calculates and retains all decimal results with up to 14 significant digits"
-
-
세상의모든계산기
카시오 fx-9860g2 설명서 중 발췌
Calculations are performed internally with a 15-digit mantissa. The result is rounded to a 10-digit mantissa before it is displayed.
-
세상의모든계산기
무려 23자리까지 늘어난 CASIO 신형 CW 계산기들
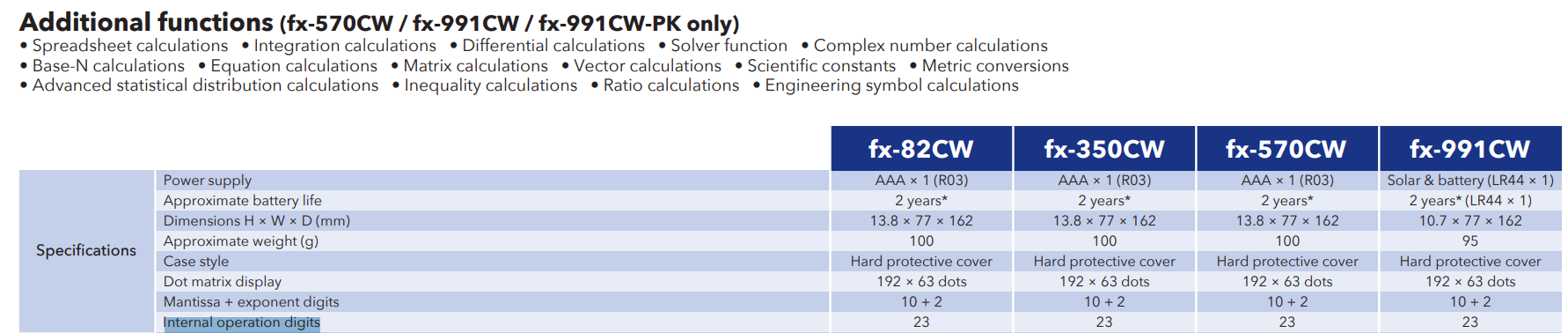
-
세상의모든계산기
https://en.wikipedia.org/wiki/Casio_V.P.A.M._calculators
ChatGPT 분석
ClassWiz CW 시리즈에서 내부 유효 자릿수가 23자리로 증가한 주요 이유는 다음과 같은 요소들이 맞물린 결과입니다:
1. ML620Q909 칩셋과 16비트 아키텍처의 도입
- CW 시리즈는 ML620Q909 칩셋을 기반으로 동작하는데, 이 칩셋은 16비트 아키텍처를 사용하여 기존 8비트 아키텍처보다 더 넓은 데이터 폭을 처리할 수 있습니다. 덕분에 한 번에 더 많은 비트를 처리할 수 있게 되어 숫자의 유효 자릿수를 더 많이 확보할 수 있습니다.
- 16비트 아키텍처는 23자리 유효 자릿수를 표현할 때 필요한 데이터량을 충분히 처리할 수 있으며, 이 과정에서 연산 속도 또한 유지할 수 있게 해줍니다.
2. 내장 BCD 코프로세서의 역할
- ML620Q909 칩셋에 포함된 BCD(이진화 십진법) 코프로세서는 특히 십진법 소수점 연산에 유리한 특성을 가지고 있습니다. BCD 코프로세서는 숫자를 십진법 형태로 다루어 부동소수점 연산 시 발생하는 오차를 줄이고 자릿수 정밀도를 유지할 수 있습니다.
- 일반적으로 이진 연산에서는 소수점 이하의 오차가 누적될 가능성이 높지만, BCD 연산을 통해 이러한 오차를 효과적으로 줄여 정확도를 높인 것이죠.
3. 23자리 지원의 필요성과 목적
- 고정밀도가 필요한 과학적 계산에서는 연산 과정에서의 오차 최소화가 중요한데, 이전 14자리 유효 자릿수보다 훨씬 많은 23자리까지 계산할 수 있도록 업그레이드한 것은 이런 요구를 반영한 것입니다.
- 특히, 공학용 계산기에서 자주 수행하는 미적분, 행렬 연산, 복소수 계산 등에서 23자리 유효 자릿수는 연산의 정확도를 크게 개선시켜 줍니다.
이처럼, ML620Q909 칩셋의 16비트 아키텍처와 BCD 코프로세서의 결합이 ClassWiz CW 시리즈가 23자리 유효 자릿수를 지원할 수 있게 된 핵심 기술적 요소라고 할 수 있습니다.
세상의모든계산기 님의 최근 댓글
ChatGPT-5 기호(÷, /, :) 자체는 의미적으로 같은 “나눗셈”을 뜻하지만, 문맥(사람이 쓰는 수학 vs 컴퓨터/프로그래밍)에 따라 해석 우선순위가 달라질 수 있습니다. 🔹 1️⃣ 전통 수학 표기 — ÷, /, : 수학 교과서, 논문, 일반 문서 등에서는 셋 다 의미적으로 “나누기”로 간주됩니다. 즉, 48÷2(9+3), 48/2(9+3), 48:2(9+3) 은 같은 의미로 받아들여야 합니다. 모두 사람의 수학 관행적 해석이 적용되어 48 ÷ 2 × (9+3) = 288 로 처리되죠. 즉, 기호가 바뀌어도 결과는 바뀌지 않습니다. 🔹 2️⃣ 컴퓨터·프로그래밍 문맥에서 / 사용 시 컴퓨터는 “생략된 곱셈(implicit multiplication)”을 따로 구분하지 못합니다. 따라서 다음 두 식은 완전히 다르게 인식됩니다. 표현 파이썬 등에서 해석 결과 48 / 2*(9+3) ((48 / 2) * (9+3)) 288 48 / 2(9+3) ❌ 문법 오류 (생략된 곱셈 인식 불가) — 즉, 컴퓨터 언어에서는 생략된 곱셈이 허용되지 않기 때문에, /는 반드시 명시적 *와 함께 써야 합니다. 🔹 3️⃣ “:” 기호의 경우 현대 수학에서는 “비율”을 나타내는 기호로 쓰입니다. a:b = \frac{a}{b} 따라서 (27 : 3(1+2)3) 같은 표현은 모호하거나 비표준적으로 간주됩니다. 대부분의 경우 계산기로는 입력 자체가 불가능합니다. ✅ 정리 기호 의미 결과 변화 주로 쓰이는 문맥 ÷ 나누기 없음 초중등 수학, 일반 표기 / 나누기 없음 (단, 프로그래밍에서는 생략 곱 불허) 수학/컴퓨터 : 비율 (또는 나누기 의미로 혼용) 보통 계산식에서는 사용 안 함 비, 비율 표기 🔹 결론 48 ÷ 2(9+3), 48/2(9+3), 48:2(9+3) 는 “수학적 의미”로는 동일하게 81로 해석됩니다. 하지만 프로그래밍이나 수식 파서(context) 에서는 /만 유효하고, 생략된 곱은 허용되지 않으며, :는 아예 다른 의미(비율)로 인식됩니다. 2025 10.28 ChatGPT-5 💯 네, 정확히 그 지점을 짚으셨어요. 요약하면 이렇게 말할 수 있습니다: “생략된 곱하기(implicit multiplication)”는 문자에서는 강한 결합력을 인정하지만, 숫자나 괄호 사이에서는 일반 곱셈(×)과 동일한 우선순위로 취급된다. 즉, 문자에서는 더 강하게 결합, 숫자·괄호 사이에서는 그냥 ‘보통 곱셈’ 으로 본다는 것이 현대 수학 표기와 계산기의 관행적 규칙입니다. 🔹 두 경우의 구조적 차이 식 형태 실제 해석 결과 결합력 특징 ab ÷ ab 문자 붙음 ((a×b) ÷ (a×b)) 1 문자 간 결합이 강함 → 한 항으로 인식 3(1+2)3 숫자·괄호 혼합 (3 × (1+2) × 3) 27 생략된 ×는 보통 곱셈 → 좌→우 규칙 적용 🔹 왜 문자식은 결합력이 더 강한가? 기호적 표현의 안정성 (ab), (xy), (2x) 같은 표기는 수백 년 동안 “하나의 곱셈 항(term)”으로 인식되어 왔습니다. 그래서 수학자들은 이걸 암묵적으로 “괄호로 묶인 덩어리”로 봅니다. ab ÷ ab = (ab) ÷ (ab) 함수 표기와 구분 필요 예: (sinx ÷ x) 에서 sinx는 sin(x)로 묶여야 의미가 있습니다. 이런 이유로 “문자 옆에 붙은 기호나 문자”는 항상 먼저 결합되도록 하는 관행이 굳어졌습니다. 🔹 반면 숫자·괄호에서는 (3(1+2)) 는 단순히 “3 × (1+2)”의 약식 표현이고, 여기서 “생략된 곱셈”은 “명시적 곱셈”과 동일한 연산자로 간주됩니다. 따라서 27 ÷ 3(1+2)3 = 27 ÷ 3 × 3 × 3 = 81 처럼 좌→우 순서로 처리합니다. 🔹 결론 생략된 곱하기(implicit multiplication)의 결합력은 표기 맥락에 따라 다르다. 문자/기호와 함께 쓰일 때 → 강하게 결합 (하나의 항으로 인식) 숫자와 괄호 사이 → 일반 곱셈과 동일한 우선순위 (좌→우 계산) 이건 “규칙이 바뀐 것”이 아니라, 표기 문법(context) 이 달라서 ‘결합 단위(token)’이 달라진 결과라고 보는 게 가장 정확합니다. 2025 10.28 자게로 이동조치하였습니다. 그리고 이 글의 내용을 정리하여 HP 포럼에 올려두었습니다. https://allcalc.org/55774 [HP Prime] Solve 함수 사용법 2025 10.27 수치해석 방법 method 를 강제로 선택할 수 있으면 좋을텐데... 위의 스샷을 보면 되는 듯 하면서도 아래 스샷을 보면 안되는 것 같기도 합니다. solve(Expr,[Var]) csolve(LstEq,LstVar) nSolve(Expr,Var,[Guess or Interval],[Method]) deSolve(Eq,[TimeVar],FncVar) linsolve(LstLinEq,LstVar) fsolve(Expr,Var,[Guess or Interval],[Method]) 2025 10.17 종합해서 답변을 드리면 HP Prime 에 solve 에서 변수명에 구간을 입력하면 수치해석 방식으로 bisection 을 사용함. 이 bisection 방식은 해의 좌-우 부호가 서로 바뀌어야만 해를 인식하고 해의 좌-우 부호가 같으면 해를 인식하지 못합니다. 이 때문에 본문 sin 의 예나 아래 사진의 예에서는 해를 인식하지 못하는 것으로 보입니다. 2025 10.17