
- 세상의 모든 계산기 자유(질문) 게시판 일반 ()
AlphaGo Zero: Learning from scratch (A.K.A 제파고)
-

- 2021.08.23 - 22:42 2017.10.19 - 09:00 4501 7
드디어 알파고의 마지막 행보 중 하나인 알파고 논문이 발표 되었습니다.
https://deepmind.com/blog/alphago-zero-learning-scratch/
아직 자세하게 읽어보진 않았지만 알파고 개발사에 대한 총정리 버전이 될 것 같습니다.
네이쳐 논문 링크 : https://www.nature.com/articles/nature24270.epdf?author_access_token=VJXbVjaSHxFoctQQ4p2k4tRgN0jAjWel9jnR3ZoTv0PVW4gB86EEpGqTRDtpIz-2rmo8-KG06gqVobU5NSCFeHILHcVFUeMsbvwS-lxjqQGg98faovwjxeTUgZAUMnRQ
눈에 띄는 점
1. Alpago Zero (A.K.A 제파고) 가 등장했습니다.
인간 기보 학습이나 인간의 어떠한 수동 조작(개입) 없이 오직 self-play training 로만 성장하게 만든 것이 Alphago Zero(A.K.A 제파고)입니다. 이러한 방법으로 단 3일만에 이전 논문의 알파고(=돌파고) 를 압살하는 수준까지 성장할 수 있었으며, 커파고(=마파고=Master) 수준까지는 21일, 커파고 보다 훨 쎈 수준까지는 40일(총 2900만판의 self-play)이 걸렸다고 말하고 있습니다. (40 Block 기준)
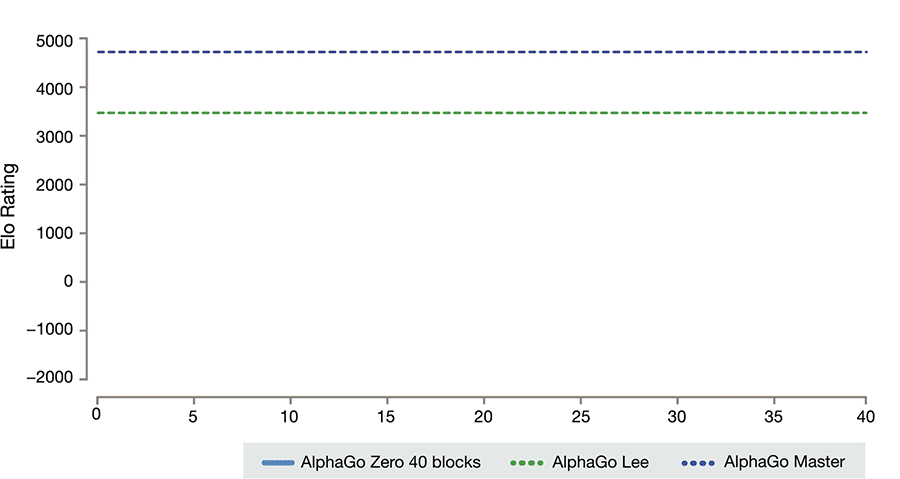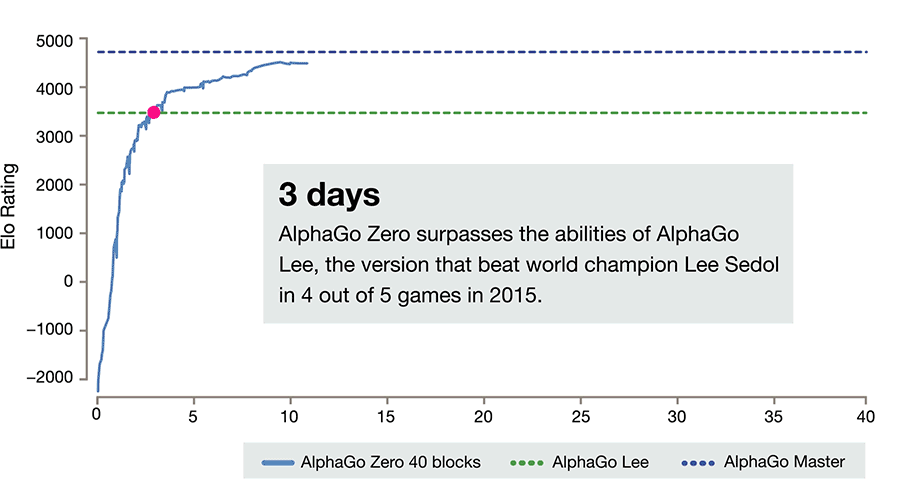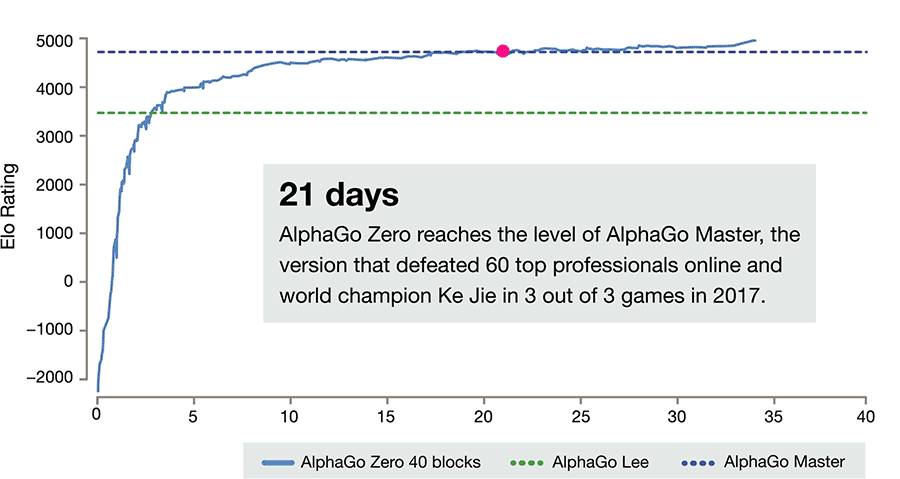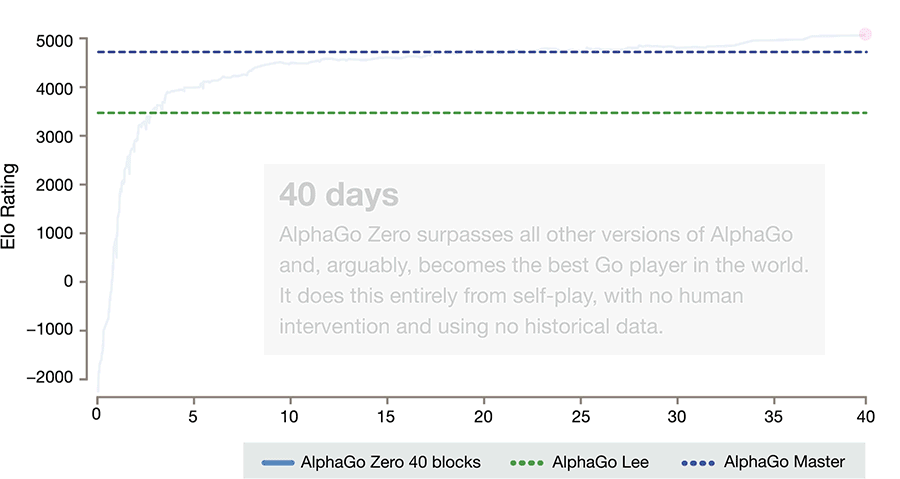
* 논문에 따르면 제파고(완성 버전)가 마파고를 89승 11패로 이겼다고 합니다. (게임당 2시간짜리 시합)
2. 기존 알파고와의 차이
기존 알파고들은 가치망(=승률분석), 정책망(=가능성 있는 다음 수 예측)이라는 2가지 신경망을 사용하였는데, 제파고는 이 둘을 통합한 단일 신경망으로 승률분석과 다음 수 예측을 모두 수행한다고 합니다. 그것이 학습이나 가치판단에 더 효율적이었다는 설명입니다.
그리고 제파고는 "rollouts" 를 하지 않는다고 합니다. (이건 잘 모르겠습니다)
* rollout = fast, random games used by other Go programs to predict which player will win from the current board position
틀린 예측 (알파고에 대한 오해)
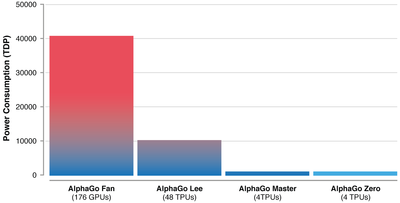
- TPU 를 보고 놀란 나머지 이전 논문에 적힌 GPU 도 혹시 TPU 인 것은 아닐까 의심했습니다.
http://www.allcalc.org/18193
"TPU 를 썼지만 공개할 시점이 아니라서 GPU 숫자로 적당히 에둘러서 표현한 것은 아닐까?" 이런 의심이었는데...
틀렸네요. 초기버전(판파고)은 GPU로 개발했고, 중간에(돌파고부터) TPU(ver.1) 로 갈아탄게 확인되었습니다.
- 돌파고(=Alphago V.18) ELO Rating 이 4500 이라는 스샷이 올라온 적이 있습니다.
http://www.allcalc.org/16539

그런데 이번 발표(그래프)를 통해서 보면 돌파고의 Elo Rating 은 3700~3800 정도로 표시되었습니다.
당시에도 같거나 더 높은 수준의 (다양한) 상대방이 없어서 (이기는 게임만 하다보니) 레이팅에 인플레이션이 있는 것 같다는 말이 있었습니다만, 제파고(의 성장)를 기준으로 Elo Rating 이 재정립된 것 같습니다.
오늘(17.10.19) 기준으로 cgos 에 있는 탑 클래스의 딥젠고 ELO가 4000 내외 수준인데 이것도 더 높은 수준의 상대내지 동급의 상대와 두는 바둑의 횟수가 늘어나면 비슷한 과정을 겪을 것 같고, 인간 최고 수준(커박)의 ELO도 인공지능과의 대국을 추가하여 재평가한다면 다소나마 약간씩 떨어질 가능성이 있어 보입니다.
* [수정] 논문에 보면 Alphago Fan(3144), Lee(3739), Master(4858), Zero(5185) 로 정확하게 나와 있습니다. 그리고, 그 산출 근거를 다음과 같이 적시하였습니다. "The results of the matches of AlphaGo Fan against Fan Hui and AlphaGo Lee against Lee Sedol were also included to ground the scale to human references, as otherwise the Elo ratings of AlphaGo are unrealistically high due to self-play bias." 알파고끼리의(아마도 여타 AI 포함일 듯) 셀프대국만 반영하면 편향으로 인해 레이팅값이 비현실적으로 높아지는데, 이를 막기 위해 인간(판후이& 이세돌)과의 대결 결과를 인간 기준 척도의 기준점으로 삼았다고 밝혔습니다. 만약 돌파고 레이팅 4500이 인간대상으로도 통하였다면 3550인 이세돌과 대국에서 승리할 확률이 99.58% 라는 말인데, 4승1패를 설명하기가 너무 곤혹스러웠던 것 같습니다.
그럼에도 불구하고 4500을 3739로 깍은 것은 너무 과격?한 것이 아닌가 싶기도 합니다. '인간과의 대결 횟수가 너무 적기 때문'입니다. 그리고 왜 판파고의 레이팅(3144)은 왜 조정하지 않았을까요? 좀 더 자세히 알아볼 필요가 있을 것 같습니다.
- 돌파고(=Alphago V.18) ELO Rating 이 4500 이라는 스샷이 올라온 적이 있습니다.
결론
제목(Learning from scratch)에서 알 수 있듯, 이번 논문의 핵심은 "인간의 개입 없이, AI의 자력으로만 바둑이라는 Category를 마스터하였으며, 그것은 인류가 아직 도달하지 못한 미지의 영역이다."는데 있겠습니다.
딥마인드(구글)은 이러한 AI의 활동 분야를 바둑이라는 Category 에 한정하지 않고 넓혀 나갈 것이고, 그로 인해 인류가 아직 밟아보지 못한 수많은 길이 새로이 열릴 것입니다.
-
25
댓글7
-
세상의모든계산기
의문점1 : 제파고의 성장은 계속될 것인가? 아니면 어느 점으로 수렴할 것인가?
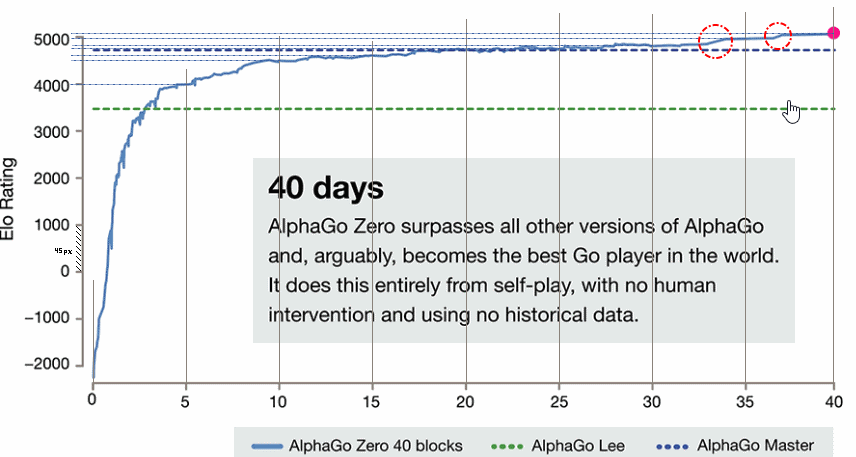
의문점2 : "완성 단계?에 이른 것인지, 성장이 더뎌졌다" 고 판단되어지는 33일 이후에 갑자기 도약하듯? 2차례 성장하였는데 제파고 내부에 어떤 변화가 있었던 것일까? (특정 정석에 대한 선택? 버림? 때문일까?)
-
세상의모든계산기
Rollout 과 관련하여 논문에 나온 내용을 뽑아보겠습니다.
- Finally, it uses a simpler tree search that relies upon this single neural network to evaluate positions and sample moves, without performing any Monte-Carlo rollouts.
- In each position st, a Monte-Carlo tree search (MCTS) αθ is executed (see Figure 2) using the latest neural network fθ. Moves are selected according to the search probabilities computed by the MCTS, at ~ πt.
- Figure 2: Monte-Carlo tree search in AlphaGo Zero.
- Monte-Carlo tree search (MCTS) may also be viewed as a form of self-play reinforcement learning.
- MCTS programs have previously achieved strong amateur level in Go, but used substantial domain expertise: a fast rollout policy, based on handcrafted features, that evaluates positions by running simulations until the end of the game; and a tree policy, also based on handcrafted features, that selects moves within the search tree.
this single neural network to evaluate positions and sample moves,without performing any Monte Carlo rollouts. -
세상의모든계산기
MCTS 를 여전히? 사용하여 (완전 랜덤은 아니지만) random 한 게임을 진행하는 것은 맞다.
마파고까지의 프로그램들은 승률 계산을 위해 rollouts(=빠르게 MCTS를 돌리는 것) 을 사용하였는데, 승률 계산을 다른 영역에 맏기므로 rollout을 할 필요가 없다.
이런 결론이네요.
Compared to the MCTS in AlphaGo Fan and AlphaGo Lee, the principal differences are that AlphaGo Zero does not use any rollouts; it uses a single neural network instead of separate policy and value networks; leaf nodes are always expanded, rather than using dynamic expansion; each search thread simply waits for the neural network evaluation, rather than performing evaluation and backup asynchronously; and there is no tree policy. A transposition table was also used in the large (40 block, 40 day) instance of AlphaGo Zero.
-

세상의모든계산기 님의 최근 댓글
- claude AI는 l-c*r^2 을 1-c*r^2 으로 잘못 읽고 표시하고 있습니다. - TI-nspire CAS 계산기에 l-c*r^2 ≥0 을 조건에 추가해 계산해 보아도 결과는 바뀌지 않습니다. 2026 07.20 ⚠️ 경고가 바로 두 번째 방법이 "성공"한 이유와 정확히 연결되어 있습니다. 경고의 의미 "Domain of the result might be larger than the domain of the input"는 CAS가 절댓값(모듈러스)을 계산하는 과정에서 원래 식보다 정의역이 더 넓은 형태로 단순화했다는 뜻입니다. 구체적으로 이 계산은 내부적으로 대략 이런 과정을 거칩니다. $$\left|\frac{er}{e\cdot r}\right| = \sqrt{\left(\frac{er}{e\cdot r}\right)\cdot\overline{\left(\frac{er}{e\cdot r}\right)}}$$ 즉 원래 식(복소수)과 그 켤레복소수를 곱해서 실수부·허수부 제곱합을 만들고, 거기에 다시 제곱근을 씌우는 과정입니다. 이 과정에서 √(x²) → x 또는 √a·√b → √(ab) 같은 규칙들이 쓰이는데, 이런 규칙들은 x가 실수이고 0 이상일 때만 엄밀하게 성립합니다. CAS는 이 조건들을 일일이 다 추적하지 않고 넘어가면서, 원래는 (e≠0, r+l·ω·i ≠ 0 등) 복소수 특유의 좁은 정의역을 가진 식을, r, l, ω가 어떤 실수여도(부호 무관하게) 정의되는 1/√(r²+l²·ω²)라는 더 넓은 정의역의 식으로 바꿔버린 것입니다. CAS는 이 손실을 감지하고 경고를 띄운 것입니다. 이게 왜 조건 대입 성공과 연결되는가 정리하면, 이 경고는 사실상 이런 뜻입니다. "나는 이 결과를 만들면서 원래 식이 가지고 있던 정의역 제약 정보(부호 조건, i 관련 조건 등)를 이미 버렸다." 바로 이 "정의역 정보를 버린" 상태가 이후 con_1 대입을 매끄럽게 만드는 원인입니다. 첫 번째 시도에서는 i가 살아있는 원래 식에 조건을 대입했기 때문에, CAS가 √(1-c·r²)이 실수인지(정의역 조건: 1-c·r² ≥ 0) 계속 추적하려고 했고, 그 정보가 con에 없어서 더 이상 정리를 못 하고 멈췄습니다. 두 번째 시도에서는 절댓값 계산 단계에서 이미 그런 세밀한 정의역 추적을 CAS 스스로 포기(단순화)했기 때문에, 이후 ω에 무리식을 대입해도 "이게 실수가 맞나?" 하는 검증 절차 없이 그냥 대수적으로 치환·정리해 버립니다. 그래서 깔끔하게 √c/√l이 나온 겁니다. 한 줄 요약 절댓값 계산 시 뜬 "정의역이 넓어졌을 수 있다"는 경고는, CAS가 그 순간에 원래 식의 엄밀한 조건(정의역)을 놓쳤다는 신호이고, 바로 그 "조건을 놓친 상태"이기 때문에 뒤에 이어지는 조건식 대입이 막힘없이 진행된 것입니다. 다만 그 대가로, 결과인 1/√(r²+l²·ω²)이나 최종 √c/√l이 원래 회로 조건(i≠0이 되는 경계, 분모가 0이 되는 경우 등)에서는 엄밀히 성립하지 않을 수 있다는 점은 감안하셔야 합니다. 실제 물리적으로는 r, l, c > 0이고 결과도 물리적으로 타당한 형태라 문제없어 보이지만, 수학적 엄밀성 측면에서는 "정의역이 넓어진 근사적 결과"라는 꼬리표가 붙어있는 셈입니다. 2026 07.20 Claude AI 답변 TI-Nspire CAS의 | (such that / 조건대입) 연산자는 대입 시점의 수식 형태를 그대로 두고 기호만 치환하는 연산입니다. 대입 후에 처음부터 다시 "실수부/허수부 분리, 유리화" 같은 재간소화를 자동으로 수행하지 않습니다. 이 차이가 지금 보신 결과 차이의 핵심입니다. 첫 번째 경우 (|er/(e·r)| | con_1 and con → 실패) 이 시점의 식은 아직 r + l·ω·i 형태의 복소수 그대로입니다 (i가 살아있음). 여기에 con_1: ω = √(1-c·r²)/(√c·l)을 대입하면, 분모 안에 i · √(1-c·r²) 라는 항이 새로 생깁니다. 문제는 CAS가 √(1-c·r²)이 실수인지(즉 1-c·r² ≥ 0인지) 판단할 근거가 없다는 겁니다. 저장해 두신 con 조건은 c>0, l>0, r>0뿐이고, 1-c·r²≥0이라는 조건은 포함되어 있지 않습니다. 그래서 CAS는 i와 이 무리식을 더 정리(유리화, 실수부·허수부 재결합)하지 못하고 있는 그대로 남겨둡니다. 결과에 여전히 i가 보이는 이유입니다. 두 번째 경우 (결과값 1/√(r²+l²·ω²)에 대입 → 성공) |er/(e·r)| (절댓값/모듈러스) 연산은 그 자체로 이미 "복소수 → 실수" 변환을 완료한 결과입니다. 즉 1/√(r²+l²·ω²)에는 더 이상 i가 없고, 순수하게 r, l, ω로만 이루어진 실수식입니다. 이 식에 ω = con_1을 대입하는 것은 그냥 실수 대수식에 실수 대입하는 것이므로, i와 무리식이 뒤엉키는 문제 자체가 발생하지 않습니다. 그래서 바로 깔끔하게 √c/√l로 정리됩니다. 정리하면 절댓값(모듈러스) 계산은 "이 값들이 실수다"라는 가정을 이미 내부적으로 써서 i를 제거하는 연산입니다. 그 연산을 조건 대입 이전에 해두면, 이후 대입은 단순 실수 대입이라 문제없이 정리됩니다. 반대로 i가 남아있는 식에 무리식을 포함한 조건을 먼저 대입하면, 그 무리식의 실수성/부호에 대한 가정이 없어서 CAS가 i를 소거하는 재간소화를 못 하고 멈춰버립니다. 실용적 팁: 복소식에 조건을 대입해야 할 때는 가능하면 절댓값·실수화(유리화) 등을 먼저 끝내서 i를 없앤 뒤 조건을 대입하거나, 대입 후 결과에 다시 simplify/expand/combine 같은 명령을 한 번 더 걸어주면 (필요한 도메인 조건과 함께) 정리가 되는 경우가 많습니다. 2026 07.19 저도 어림잡아 추측할 뿐이지 정확한 이유를 알지는 못합니다. 질문하신 사진을 그대로 (Gemini 3.5 Flash / ChatGPT / Claude Sonnet 5) AI에 넣어 보니 claude AI 가 제일 합리적인 답변을 주어서 이를 붙여 넣습니다. 2026 07.19 아 그렇네요. 감사합니다. ^^ 2026 04.28