
- 세상의 모든 계산기 자유(질문) 게시판 일반 ()
알파고 2.0 ??
-

- 2022.12.02 - 12:36 2017.05.25 - 21:40 1265 13
1. 경향신문 기사 中
작년 3월 이세돌 대국 당시 알파고는 구글이 개발한 AI용 칩인 ‘TPU’ 50개를 동원하는 등 대규모 전산 설비를 썼지만, 올해에는 TPU 4개를 얹은 산업용 컴퓨터(machine) 1대만 썼다.
원문보기:
http://news.khan.co.kr/kh_news/khan_art_view.html?artid=201705251847001&code=970204&nv=stand&utm_source=naver&utm_medium=newsstand&utm_campaign=row1_4#csidx014b2a168e8fece83d99057dbfba69d

2. 블로터 기사 中
이세돌 9단과 대국한 알파고는 구글 클라우드 상 50개의 TPU(Tensor Processing Unit)를 사용했다. TPU는 구글이 머신러닝을 위해 특별히 제작한 처리장치다. 1초에 50개의 수와 10만개의 형태를 탐색할 수 있었다. 현재 커제 9단과 대국 중인 알파고는 ‘알파고 마스터’라고 불리는 버전이다. 이번 구글 I/O 에서 공개된 단일 TPU 머신을 사용하며 2016년 버전 대비 10분의 1의 컴퓨팅 파워를 사용하면서도 더 빨리 계산한다.
http://www.bloter.net/archives/280664
3. NEXTPLATFORM - TPU2에 대한 기사 中
Google’s first generation TPU consumed 40 watts at load while performing 16-bit integer matrix multiplies at a rate of 23 TOPS. Google doubled that operational speed to 45 TFLOPS for TPU2 while increasing the computational complexity by upgrading to 16-bit floating point operations. A rough rule of thumb says that is at least two doublings of power consumption – TPU2 must consume at least 160 watts if it does nothing else other than double the speed and move to FP16. The heat sink size hints at much higher power consumption, somewhere above 200 watts.
https://www.nextplatform.com/2017/05/22/hood-googles-tpu2-machine-learning-clusters/
-
25
댓글13
-
세상의모든계산기
In-Datacenter Performance Analysis of a Tensor Processing Unit ™
https://drive.google.com/file/d/0Bx4hafXDDq2EMzRNcy1vSUxtcEk/view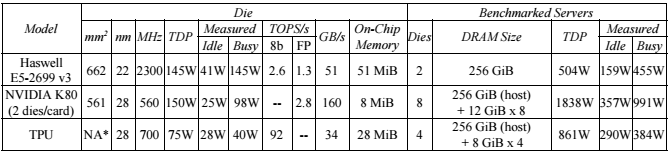
※ 이 논문은 TPU2 가 아닌 TPU(1세대) 을 대상으로 작성된 논문입니다.
-
세상의모든계산기
NVIDIA V100
출처 : https://devblogs.nvidia.com/parallelforall/inside-volta/?ncid=so-fac-vt-13920
Tesla V100 delivers industry-leading floating-point and integer performance. Peak computation rates (based on GPU Boost clock rate) are:
7.5 TFLOP/s of double precision floating-point (FP64) performance;
15 TFLOP/s of single precision (FP32) performance;
120 Tensor TFLOP/s of mixed-precision matrix-multiply-and-accumulate.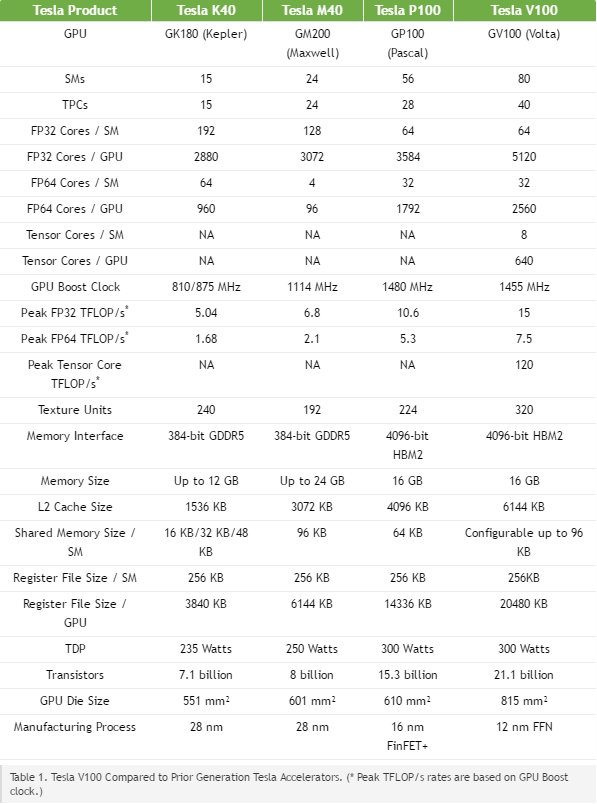
-
세상의모든계산기
팩트 정리를 해 보면...
1. 돌파고의 TPU는 TPU1 으로 불림2. 커파고의 TPU는 TPU2 로 불림
(칩을 TPU2 Chip 으로 부르기도 하는 듯)3. TPU2 모듈 1개는 TPU2코어 4개로 구성
4. TPU2 모듈의 성능 = 45테라플롭스/개*4개 = 180테라플롭스 (
5. https://www.tensorflow.org/tfrc/ 구글 텐서 크라우드?는 100개의 TPU2 모듈로 구성
각각의 TPU2 칩은 두개의 BlueLink 25GB/s 케이블로 연결 -
세상의모든계산기
추정
CPU 종류와 그 비율
출처 : https://www.nextplatform.com/2017/05/22/hood-googles-tpu2-machine-learning-clusters/
We believe that Google connected each CPU board to exactly one TPU2 board using both OPA cables to achieve 25 GB/s aggregate bandwidth. This one-to-one connectivity answers a key question for TPU2 – Google designed the TPU2 stamp with a 2:1 ratio of TPU2 chips to Xeon sockets. That is, four TPU2 chips for every dual-socket Xeon server.> 클라우드가 아닌 싱글머쉰에서 알파고가 돌아갔다면 제온 2소켓 보드 + TPU2 모듈*1개 구성이 맞는 듯
> CPU는 구글 문서에 나온대로 INTEL XEON E5-2699v3 인것 같음. 실질적 계산 역할은 그리 크지 않은 듯.
(seldom 하게 2.3GHz 이외 클럭으로 동작)> 전력소모는 구글 문서에 나온대로 TDP 861W, IDLE 290W, BUSY 384W (싱글머쉰 기준) 이 맞는 듯

세상의모든계산기 님의 최근 댓글
참고 - [공학용 계산기] 로그의 입력 (log, ln) (feat. 밑 입력이 안되는 계산기는?) https://allcalc.org/14995 2025 11.14 HP-39gII 에 ExistOS 설치하기 https://allcalc.org/38526 2025 11.07 1. 왜 검은색이 아닌 다른 색으로 보일까? (제공된 LUT 필터) 제가 제공해 드린 magenta_lens.cube LUT 필터는 540~560nm(녹색-노란색) 파장대의 색상을 '완전히 제거(검은색으로 만듦)'하는 대신, '다른 색상으로 왜곡/변환'하도록 설계되었습니다. * 원리: LUT(Look-Up Table)는 특정 입력 색상(Input RGB)을 미리 정해진 다른 출력 색상(Output RGB)으로 매핑하는 테이블입니다. 이 LUT는 540~560nm에 해당하는 RGB 값들이 들어오면, 검은색(0, 0, 0)이 아닌, 매우 어둡거나 채도가 낮은 특정 색(예: 어두운 올리브색, 갈색 등)으로 변환하라고 지시합니다. * 의도: * 현실적인 물리 필터 시뮬레이션: 실제 고가의 색약 보정 안경도 특정 파장을 100% 완벽하게 차단하지는 못합니다. 빛의 일부를 흡수하고 일부는 통과시키거나 변환하는데, 이 LUT는 그러한 현실 세계의 필터 효과를 더 비슷하게 흉내 냈을 수 있습니다. * 시각적 정보 유지: 특정 색을 완전히 검게 만들면 그 부분의 형태나 질감 정보가 완전히 사라집니다. 하지만 다른 어두운 색으로 대체하면, 색상 정보는 왜곡되더라도 밝기나 형태 정보는 어느 정도 유지되어 전체적인 이미지가 덜 어색하게 보일 수 있습니다. 결론적으로, 스펙트럼 그림에서 해당 대역의 색이 갑자기 '다른 색으로 툭 바뀌는' 현상은, LUT 필터가 "이 파장대의 색은 앞으로 이 색으로 표시해!"라고 강제적으로 지시한 결과이며, 이것이 바로 이 필터가 작동하는 방식 그 자체입니다. 2. 왜 'Color Vision Helper' 앱은 검은색으로 보일까? 비교하신 'Color Vision Helper' 앱은 노치 필터의 원리를 더 이상적(Ideal)이고 교과서적으로 구현했을 가능성이 높습니다. * 원리: "L-콘과 M-콘의 신호가 겹치는 540~560nm 파장의 빛은 '완전히 차단'되어야 한다"는 개념에 매우 충실한 방식입니다. * 구현: 따라서 해당 파장에 해당하는 색상 정보가 들어오면, 어떠한 타협도 없이 그냥 '검은색(RGB 0, 0, 0)'으로 처리해 버립니다. 이는 "이 파장의 빛은 존재하지 않는 것으로 처리하겠다"는 가장 강력하고 직접적인 표현입니다. 2025 11.06 적용사례 4 - 파장 스펙트럼 https://news.samsungdisplay.com/26683 ㄴ (좌) 연속되는 그라데이션 ➡️ (우) 540 이하 | 구분되는 층(색) | 560 이상 - 겹치는 부분, 즉 540~560 nm 에서 색상이 차단? 변형? 된 것을 확인할 수 있음. 그럼 폰에서 Color Vision Helper 앱으로 보면? ㄴ 540~560 nm 대역이 검은 띠로 표시됨. 완전 차단됨을 의미 2025 11.05 빨간 셀로판지로도 이시하라 테스트 같은 숫자 구분에서는 유사한 효과를 낼 수 있다고 합니다. 색상이 다양하다면 빨강이나, 노랑, 주황 등도 테스트해보면 재밌겠네요. 2025 11.05